 xpdf afl fuzz
xpdf afl fuzz
# xpdf afl fuzz
记录一次失败的fuzz经历,
其实去年九月有fuzz过pycdc但是一直没有笔记,过年的时候更换系统文件都丢了,觉得很可惜,于是这次稍微记录一下,
因为工作原因在写golang, 然后在fuzz测试过程中写了一些小工具都是python,
xpdf这个cpp让我看的非常之 噎得慌
# fuzz 部分
因为也没什么好想法去魔改fuzzer,就是直接开始aflpp跑了,目标也有源码直接可以标准的进行测试。
我在mozila/pdf.js/test (opens new window)找到了大量的输入样例,然后直接开始跑。
# crash分类
跑了大概三四个小时?大概出现了36k左右的crash, afl会记录非重复的crash, 于是只有780左右被记录了下来,
然后面临第一个问题是如何进行crash分类, 之前pycdc的fuzz中我编写过一个 生成gdb脚本然后获取gdb logfile并通过其中的栈回溯进行分类的小工具,效果还可,但是没封装到一块,好几个指令显得有点笨。
然后看了下afl-utils (opens new window)工具, 发现他其实也是这个思路,而且其中的gdb脚本直接用了另一个项目exploitable (opens new window),
但是这里有很多比较粗糙的地方,
- 对于重复的判断只是通过文件的hash,
- 可能出现很多相同的crash, 按照栈回溯去重更稳妥一些。
- 在获取gdb运行结果的时候直接通过
subprocess.check_output进行,- 主要是没有管其他插件的加载问题, 万一有个gef pwngdb, 那么这个每次运行整个context都会被检测一遍,这个简直不可忍受。
于是我对这个程序进行了一些小修改 (opens new window),主要是以上两点。
然后对于exploitable, 增加了一个对于是否在运行的检测 (opens new window),有一些crash崩溃后直接退出,运行exploitable的话会报错, 这一部分的原因我还没搞清楚。
于是经过这两个工具的处理,上面的780左右的crash剩下了33个,
这里我发现了一个这套工具存在的问题:
- 对于栈回溯的判断是整个栈回溯的hash, 会有一些崩溃点相同的crash,
这个问题的话,可以增加一个对于crash崩溃点向上两/三层的记录+比较,但是也会不太稳,决定宁可误判不能放过,没改。
然后人工稍微看一下,就剩下了7个crash。
# 分析
# gmallocn
这个比较简单,其实就是xpdf内部内存全部使用统一的接口去申请,然后如果过大会触发gMemError
void *gmallocn(int nObjs, int objSize) GMEM_EXCEP {
int n;
if (nObjs == 0) {
return NULL;
}
n = nObjs * objSize;
if (objSize <= 0 || nObjs < 0 || nObjs >= INT_MAX / objSize) {
gMemError("Bogus memory allocation size");
}
return gmalloc(n);
}
2
3
4
5
6
7
8
9
10
11
12
这个就是检查出错了,但是因为下层有调用throw 会触发crash.
# dos
有三个不同的dos洞, 发现这种东西确实特别容易写出来dos, 只要引用循环基本上就会开始无限递归。
分别是这三个位置 Catalog::countPageTree, Catalog::readPageLabelTree2, AcroForm::scanField
然后看了下论坛发现大伙都已经交过了,而且作者说下个大版本xpdf 5系列会加入对象引用循环的检测,这几个crash也索然无味。
# null指针引用
stack_frame_hash: 3472571ec2746ce0aafa603325b09e70
stack_frame
/home/wlz/lab/fuzz/Fuzzing101/fuzzing_xpdf/install/pdftotext!XFAScanner::getFieldValue+0x0
/home/wlz/lab/fuzz/Fuzzing101/fuzzing_xpdf/install/pdftotext!XFAScanner::scanField+0x0
/home/wlz/lab/fuzz/Fuzzing101/fuzzing_xpdf/install/pdftotext!XFAScanner::scanNode+0x0
/home/wlz/lab/fuzz/Fuzzing101/fuzzing_xpdf/install/pdftotext!XFAScanner::scanNode+0x0
/home/wlz/lab/fuzz/Fuzzing101/fuzzing_xpdf/install/pdftotext!XFAScanner::load+0x0
/home/wlz/lab/fuzz/Fuzzing101/fuzzing_xpdf/install/pdftotext!AcroForm::load+0x0
/home/wlz/lab/fuzz/Fuzzing101/fuzzing_xpdf/install/pdftotext!Catalog::Catalog+0x0
/home/wlz/lab/fuzz/Fuzzing101/fuzzing_xpdf/install/pdftotext!PDFDoc::setup2+0x0
/home/wlz/lab/fuzz/Fuzzing101/fuzzing_xpdf/install/pdftotext!PDFDoc::setup+0x0
/home/wlz/lab/fuzz/Fuzzing101/fuzzing_xpdf/install/pdftotext!PDFDoc::PDFDoc+0x0
/home/wlz/lab/fuzz/Fuzzing101/fuzzing_xpdf/install/pdftotext!main+0x0
INVOKING_0
2
3
4
5
6
7
8
9
10
11
12
13
14
这个也没啥用,
在函数XFAScanner.cc: XFAScanner::scanNode函数中,调用函数XFAScanner::scanField,
传入的第二个参数默认值为0, 在if语句中进行复制,则可以不进行赋值直接进入函数运行,传入0,
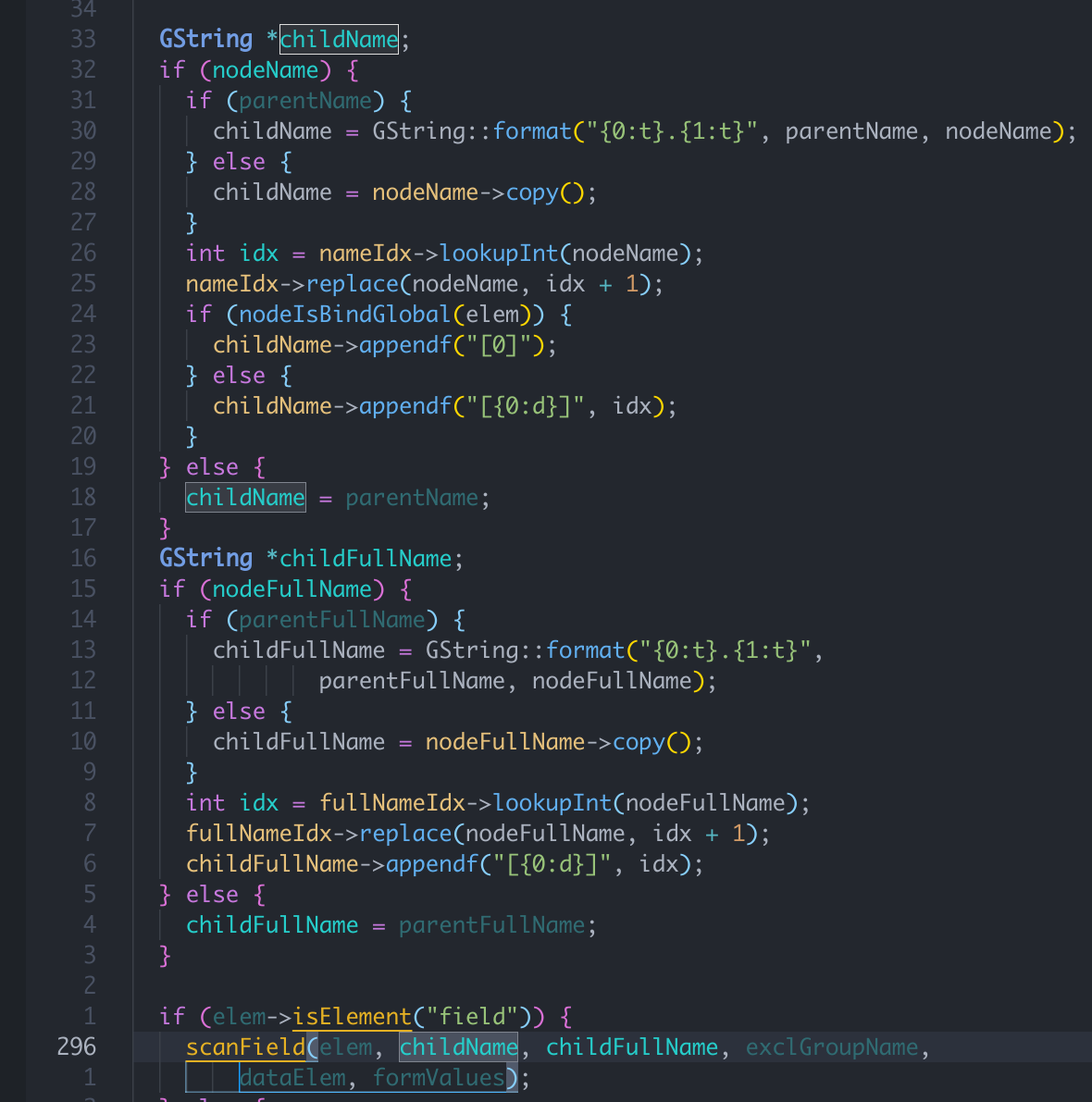
然后传入下层函数,
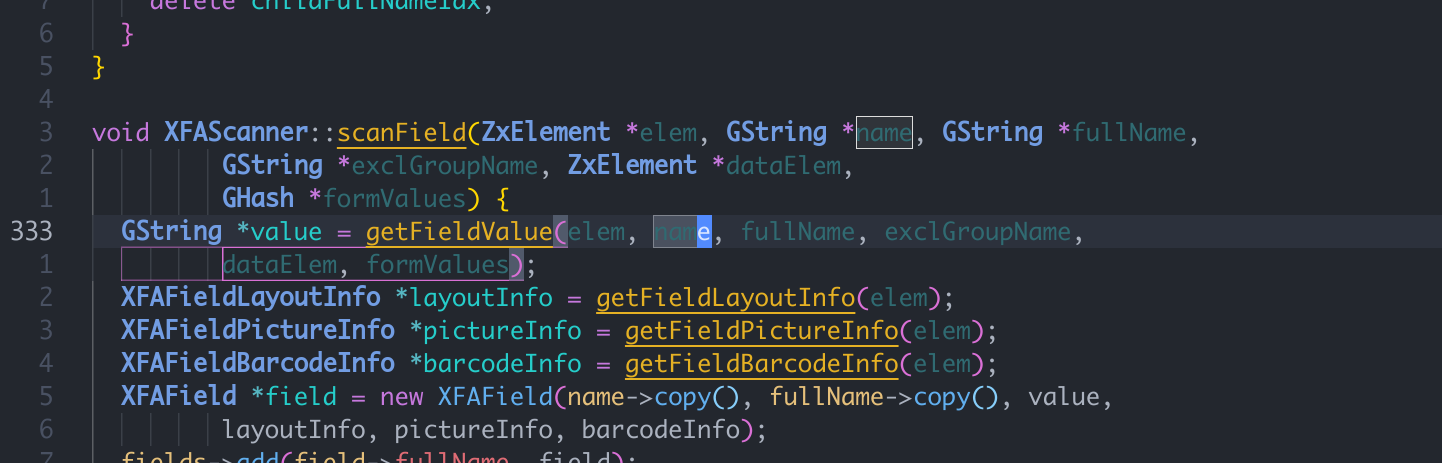
XFAScanner::getFieldValue中, 会尝试获取这个name->getCString这时候会使用这个0进行引用。
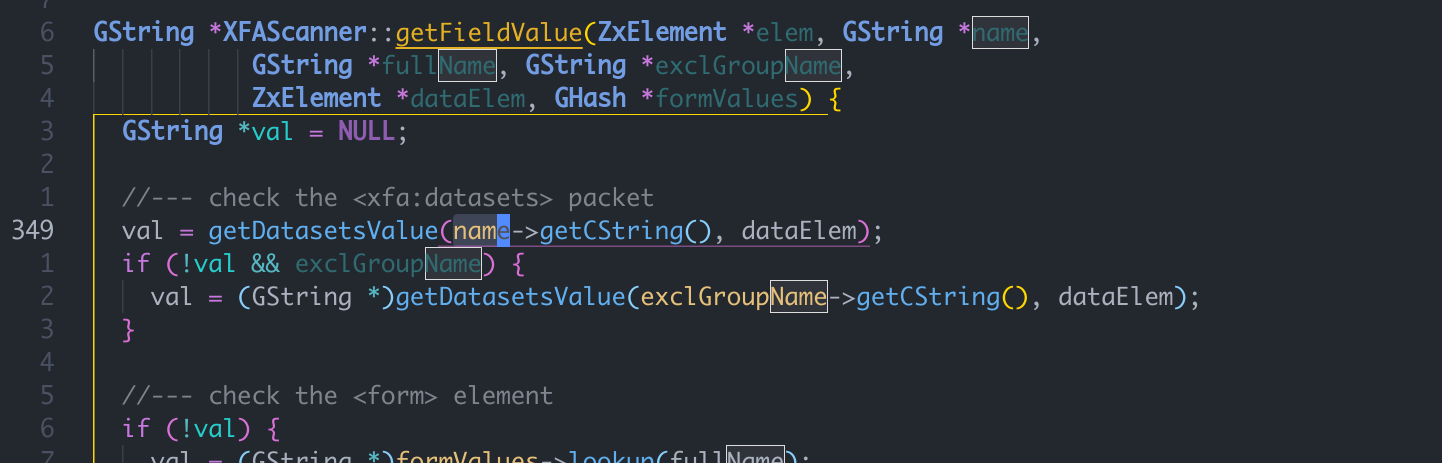
无法利用。
# while 1
出现了一个死循环的crash, 但是不会导致程序崩溃, 在尝试跟踪。
# 改进
以后应该看一下结构化fuzz之类实现,afl的bit级别的变异对于纯二进制文件来说挺合适的,但是pdf中只有stream中是这样的, 整体来说pdf还是有自己的比较严格的格式的文件,afl的变异策略并不适合来进行pdf的fuzz。