 libfuzzer source code analysis
libfuzzer source code analysis
# libfuzzer source code analysis
libfuzzer 简单源码分析
# 使用
libfuzz使用可以参考这个项目, libfuzz-workshop (opens new window), 其内部也有一个单独取出来的libfuzz源码,但是和我本地版本不对应,就没直接使用。
libfuzzer使用:
编写一个loader, 将 extern "C" int LLVMFuzzerTestOneInput(const uint8_t *Data, size_t Size) 实现, 这个size和data就是fuzz输入进来的数据,一般实现如下:
extern "C" {
int LLVMFuzzerTestOneInput(const uint8_t *Data, size_t Size){
FuzzTargetApi(Data, Size);
}
}
2
3
4
5
然后使用clang进行编译, 常用编译选项:
- -fsanitize=
- fuzzer: 使用libfuzzer, 会自动读取到
LLVMFuzzerTestOneInput函数,将libfuzz的代码链接在一起, 可以追加-DLLVMFuzzerTestOneInput=FunctionName编译选项, 将认为给定的函数是LLVMFuzzerTestOneInput - address: 启动
AddressSanitizer功能, 这是llvm中的对内存进行检查的功能, 因为fuzz是检查崩溃或超时等异常引号,对于溢出特别是短字节溢出没有很好的效果,在afl和libfuzzer中我们都会使用这个编译选项。 - fuzzer-no-link: 在fuzz一些库函数的时候会用到,在编译的时候开启这个选项, 会对库函数内增加fuzz需要的插桩,但是不会立刻生成fuzz程序,而是生成一个
xx.a文件,用于后续和loader链接在一起。
- fuzzer: 使用libfuzzer, 会自动读取到
- -fsantize-coveraeg=
- 这部分是llvm在ir层面的插桩, 增加以下几个选项会开启对应的插桩,
这部分llvm实现的非常聪明, 插桩实在ir优化的时候做的,但是只是插入代码,详细的实现其实是在libfuzzer的代码中,这样libfuzzer在运行时就可以获取到覆盖率信息。
- trace-cmp
- trace-div
- trace-gep
- trace-pc-guard
一般使用流程: 首先编译出静态链接库,
export FUZZ_CXXFLAGS="-O2 -fno-omit-frame-pointer -g -fsanitize=address,fuzzer-no-link -fsanitize-coverage=trace-cmp,trace-gep,trace-div"
./configure CC="clang" CFLAGS="$FUZZ_CXX_FLAGS" CXX="clang++"
make -j8
2
3
生成xx.a文件,然后和编译出fuzz,
clang++ -std=c++11 fuzzer.cc -O2 -fno-omit-frame-pointer -g -fsanitize=address,fuzzer -fsanitize-coverage=tracecmp,trace-gep,trace-div -I include/ xxx.a -lz -o fuzz
然后生成我们的fuzz文件,直接运行即可,libfuzz会在遇到第一个崩溃的时候自动停止。
还有一些非常有用的选项,可以在libfuzzer-workshop中看到,我们后面源码分析中也会讲到一些。
一个比较重要的事情是要意识到, libfuzzer主要针对某一个api进行fuzz, afl则是对于程序整体进行fuzz。
其实有点像go的test, 或者go新出的原生fuzz库的使用,即 编译器级别的测试拓展做出来的fuzz功能。
# 环境搭建
libfuzzer其实是被包含在llvm项目中的,目录在llvm/compile-rt/lib/fuzzer, 这一部分是解耦出来的,可以直接使用这一部分源码和对应版本clang进行编译和调试。
这样就不需要编译巨大的llvm了。
直接在fuzzer目录运行build.sh脚本即可, 会编译相关文件并组合成libFuzzer.a文件。
这个libFuzzer.a文件编译其实就和我们前面看到的一样,
clang++ -std=c++11 fuzz.cpp -fsanitize=address -fsanitize-coverage=trace-cmp,trace-div,trace-gep ./libFuzzer.a -lz -o fuzz
然后应该可以通过二进制文件开始调试了。
# 源码分析
libfuzzer其实做的事情就是,构造好输入数据,然后调用我们编写的LLVMFuzzerTestOneInput, 并将数据输入。
工作工程大概是:
- 初始化
- 生成数据
- 开始测试
- 收集覆盖率 -> 回到数据生成部分
直到fuzz到crash以后,会根据jobs的设置推出,一般设置为0,就是得到一个crash就退出。
# 初始化
分析的起点从main函数开始,libfuzzer的mian函数在文件FuzzerMain.cpp文件中, 声明了函数LLVMFuzzerTestOneInput, 并作为参数传入了函数fuzzer::FuzzerDriver,
这个函数首先会读取参数并加载各种配置项, 列几个出现的重要的变量:
- EF:
ExternalFunctions: 表示外部函数, 其实是类似LLVMFuzzerTestOneInput之类的函数,在libfuzz中声明了,但是不一定真的被用户实现了,如果被用户实现了,会在这个变量中对应的位置记录对应地址,可以直接进行调用, 这样的设计给整个fuzz提供了一定的拓展能力。 - Flags: 在
FuzzerFlags.def文件中的各种相关定义,这里面的是默认定义,默认被载入,然后在我们运行ParseFlags(Args, EF)的时候会从命令行参数和是否存在外部函数来调整flag中的配置。 - FuzzingOptions: 其实是将
Flags的内容基本转换过来, 后续传入比较重要的几个对象中。
主要对这几个配置相关的变量进行初始化和设置。
然后开始进行运行, 创建了三个重要的运行相关的对象。
Random Rand(Seed);
auto *MD = new MutationDispatcher(Rand, Options);
auto *Corpus = new InputCorpus(Options.OutputCorpus, Entropic);
auto *F = new Fuzzer(Callback, *Corpus, *MD, Options);
2
3
4
- MutationDispatcher: 这是变异相关的控制器,libfuzzer中默认存在13种变异方式。如果
EF中存在自定义变异算法,会直接使用用户提供的自定义变异。
libfuzzer的变异分发这部分,比afl写的清晰太多了 qaq, afl一个fuzzone函数全仍里头 ->_->
- InputCorpus: 这是输入的语料
- Fuzzer: 这是主要函数,主要的fuzz行为都是这个对象。注意
Callback这个参数,这个是我们看到main函数传入的第二个参数, 也就是我们自定义的LLVMFuzzerTestOneInput函数,
后续继续进行一些初始化操作, 然后进入函数Fuzzer::Loop
auto CorporaFiles = ReadCorpora(*Inputs, ParseSeedInuts(Flags.seed_inputs));
F->Loop(CorporaFiles);
2
# 运行逻辑
因为是针对函数的fuzz, 因此不需要afl那样fork-server之类的设计,但是同样失去了对于运行空间重置的能力,可能每次运行状态不同。
但是实现上来说,这种方案确实简单不少。
# Fuzzer::Loop
void Fuzzer::Loop(Vector<SizedFile> &CorporaFiles) {
auto FocusFunctionOrAuto = Options.FocusFunction;
DFT.Init(Options.DataFlowTrace, &FocusFunctionOrAuto, CorporaFiles,
MD.GetRand());
TPC.SetFocusFunction(FocusFunctionOrAuto);
ReadAndExecuteSeedCorpora(CorporaFiles);
DFT.Clear(); // No need for DFT any more.
TPC.SetPrintNewPCs(Options.PrintNewCovPcs);
TPC.SetPrintNewFuncs(Options.PrintNewCovFuncs);
system_clock::time_point LastCorpusReload = system_clock::now();
TmpMaxMutationLen =
Min(MaxMutationLen, Max(size_t(4), Corpus.MaxInputSize()));
2
3
4
5
6
7
8
9
10
11
12
13
首先进入函数,初始化DTF和TPC, 分别表示DataFlowTrace和TracePC,
然后先运行用户给定的语料, 确定一下目前的覆盖率,
然后开始进入循环
while (true) {
auto Now = system_clock::now();
if (!Options.StopFile.empty() &&
!FileToVector(Options.StopFile, 1, false).empty())
break;
if (duration_cast<seconds>(Now - LastCorpusReload).count() >=
Options.ReloadIntervalSec) {
RereadOutputCorpus(MaxInputLen);
LastCorpusReload = system_clock::now();
}
if (TotalNumberOfRuns >= Options.MaxNumberOfRuns)
break;
if (TimedOut())
break;
// Update TmpMaxMutationLen
if (Options.LenControl) {
if (TmpMaxMutationLen < MaxMutationLen &&
TotalNumberOfRuns - LastCorpusUpdateRun >
Options.LenControl * Log(TmpMaxMutationLen)) {
TmpMaxMutationLen =
Min(MaxMutationLen, TmpMaxMutationLen + Log(TmpMaxMutationLen));
LastCorpusUpdateRun = TotalNumberOfRuns;
}
} else {
TmpMaxMutationLen = MaxMutationLen;
}
// Perform several mutations and runs.
MutateAndTestOne();
PurgeAllocator();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
首先是判断时间和运行次数等,决定是否退出,然后更新一下编译的最大长度,而后进入MatateAndTestOne函数,进行变异和运行。
# Fuzzer::MutateAndTestOne
void Fuzzer::MutateAndTestOne() {
MD.StartMutationSequence();
auto &II = Corpus.ChooseUnitToMutate(MD.GetRand());
if (Options.DoCrossOver) {
auto &CrossOverII = Corpus.ChooseUnitToCrossOverWith(
MD.GetRand(), Options.CrossOverUniformDist);
MD.SetCrossOverWith(&CrossOverII.U);
}
const auto &U = II.U;
memcpy(BaseSha1, II.Sha1, sizeof(BaseSha1));
assert(CurrentUnitData);
size_t Size = U.size();
assert(Size <= MaxInputLen && "Oversized Unit");
memcpy(CurrentUnitData, U.data(), Size);
assert(MaxMutationLen > 0);
size_t CurrentMaxMutationLen =
Min(MaxMutationLen, Max(U.size(), TmpMaxMutationLen));
assert(CurrentMaxMutationLen > 0);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
函数开始, 主要是一些变量的初始化,比较重要的是II, 这是一个InputInfo结构体,表示一个输入的语料, 通过之前提到的InputCorpus对象管理,定义在 Vector<InputInfo*> InputCorpus::Inputs;, 这里通过函数获取, 其实就是随机选择一个出来。
InputInfo &ChooseUnitToMutate(Random &Rand) {
InputInfo &II = *Inputs[ChooseUnitIdxToMutate(Rand)];
assert(!II.U.empty());
return II;
}
2
3
4
5
接下来是变异和运行部分。
for (int i = 0; i < Options.MutateDepth; i++) {
if (TotalNumberOfRuns >= Options.MaxNumberOfRuns)
break;
MaybeExitGracefully();
size_t NewSize = 0;
if (II.HasFocusFunction && !II.DataFlowTraceForFocusFunction.empty() &&
Size <= CurrentMaxMutationLen)
NewSize = MD.MutateWithMask(CurrentUnitData, Size, Size,
II.DataFlowTraceForFocusFunction);
// If MutateWithMask either failed or wasn't called, call default Mutate.
if (!NewSize)
NewSize = MD.Mutate(CurrentUnitData, Size, CurrentMaxMutationLen);
assert(NewSize > 0 && "Mutator returned empty unit");
assert(NewSize <= CurrentMaxMutationLen && "Mutator return oversized unit");
Size = NewSize;
II.NumExecutedMutations++;
Corpus.IncrementNumExecutedMutations();
bool FoundUniqFeatures = false;
bool NewCov = RunOne(CurrentUnitData, Size, /*MayDeleteFile=*/true, &II,
/*ForceAddToCorpus*/ false, &FoundUniqFeatures);
TryDetectingAMemoryLeak(CurrentUnitData, Size,
/*DuringInitialCorpusExecution*/ false);
if (NewCov) {
ReportNewCoverage(&II, {CurrentUnitData, CurrentUnitData + Size});
break; // We will mutate this input more in the next rounds.
}
if (Options.ReduceDepth && !FoundUniqFeatures)
break;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
通过函数MD.MutateWithMask和函数MD.Mutate进行变异,然后通过函数RunOne进行运行测试,如果返回出现了新的路径的话, 会退出。
for循环的判断条件是 Options.MutateDepth.
# ExecuteCallback
进入Fuzzer::RunOne函数以后,首先是运行函数ExecuteCallback
首先是准备数据,主要是DataCopy,
ATTRIBUTE_NOINLINE void Fuzzer::ExecuteCallback(const uint8_t *Data,
size_t Size) {
TPC.RecordInitialStack();
TotalNumberOfRuns++;
assert(InFuzzingThread());
// We copy the contents of Unit into a separate heap buffer
// so that we reliably find buffer overflows in it.
uint8_t *DataCopy = new uint8_t[Size];
memcpy(DataCopy, Data, Size);
if (EF->__msan_unpoison)
EF->__msan_unpoison(DataCopy, Size);
if (EF->__msan_unpoison_param)
EF->__msan_unpoison_param(2);
if (CurrentUnitData && CurrentUnitData != Data)
memcpy(CurrentUnitData, Data, Size);
CurrentUnitSize = Size;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
以下代码中比较重要的位置是CB(DataCopy, Size), 因为这个CB其实是fuzzer对象初始化的时候传入的Callback参数, 也就是我们定义的LLVMFuzzerTestOneInput,
其他部分主要是对于获取覆盖率相关的操作,我们后续会讲到。
{
ScopedEnableMsanInterceptorChecks S;
AllocTracer.Start(Options.TraceMalloc);
UnitStartTime = system_clock::now();
TPC.ResetMaps();
RunningUserCallback = true;
int Res = CB(DataCopy, Size);
RunningUserCallback = false;
UnitStopTime = system_clock::now();
(void)Res;
assert(Res == 0);
HasMoreMallocsThanFrees = AllocTracer.Stop();
}
if (!LooseMemeq(DataCopy, Data, Size))
CrashOnOverwrittenData();
CurrentUnitSize = 0;
delete[] DataCopy;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
最后经过简单的处理即可退出, 注意LooseMemeq这个位置,如果运行前后的数据被修改了的话,会直接认为是crash,
但是似乎定义是
LLVMFuzzerTestOneInput(const size_8* Data, size_t Size), 应该是不会被修改才对。
# 多线程运行
# RunInMultipleProcesses
让我们回到最开始,我们前面提到过,libfuzz一般遇到某个crash以后会直接退出, 如果想类似afl一样并行进行fuzz的话可以使用 work 和 job达到类似效果
定义在FuzzerFlag.def文件中
FUZZER_FLAG_UNSIGNED(jobs, 0, "Number of jobs to run. If jobs >= 1 we spawn"
" this number of jobs in separate worker processes"
" with stdout/stderr redirected to fuzz-JOB.log.")
FUZZER_FLAG_UNSIGNED(workers, 0,
"Number of simultaneous worker processes to run the jobs."
" If zero, \"min(jobs,NumberOfCpuCores()/2)\" is used.")
2
3
4
5
6
jobs表示,我们预计运行多少个并行的fuzz程序, workers表示我们libfuzzer会具体分成多少个线程去并发执行。
在默认情况下,libfuzzer只是单线程运行, 在函数 FuzzerDriver中, 对并发执行这部分做出实现
if (Flags.jobs > 0 && Flags.workers == 0) {
Flags.workers = std::min(NumberOfCpuCores() / 2, Flags.jobs);
if (Flags.workers > 1)
Printf("Running %u workers\n", Flags.workers);
}
if (Flags.workers > 0 && Flags.jobs > 0)
return RunInMultipleProcesses(Args, Flags.workers, Flags.jobs);
2
3
4
5
6
7
8
9
可以看到,如果jobs存在的话,会设置默认的workers, 也可以手动指定。
这两个参数直接传入RunInMultipleProcesses函数,进行并发运行,
这个函数实现也很简单, 就是去掉jobs和workers选项, 然后开启workers数量的线程来运行libfuzzer,
static int RunInMultipleProcesses(const Vector<std::string> &Args,
unsigned NumWorkers, unsigned NumJobs) {
std::atomic<unsigned> Counter(0);
std::atomic<bool> HasErrors(false);
Command Cmd(Args);
Cmd.removeFlag("jobs");
Cmd.removeFlag("workers");
Vector<std::thread> V;
std::thread Pulse(PulseThread);
Pulse.detach();
for (unsigned i = 0; i < NumWorkers; i++)
V.push_back(std::thread(WorkerThread, std::ref(Cmd), &Counter, NumJobs, &HasErrors));
for (auto &T : V)
T.join();
return HasErrors ? 1 : 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# fork模式
还可以通过-fork=x选项启动fork模式,看起来是上面提到的jobs和works的融合提高版?
if (Flags.fork)
FuzzWithFork(F->GetMD().GetRand(), Options, Args, *Inputs, Flags.fork);
2
有一个特别点在于,fork的判断和运行其实是在jobs运行之后的,也就是说如果同时设置,会先运行jobs的逻辑,
首先会创建一个临时目录, 存放所需要的信息,这是有个一定目录结构的,
然后进行对线程的设置和启动,
size_t JobId = 1;
Vector<std::thread> Threads;
for (int t = 0; t < NumJobs; t++) {
Threads.push_back(std::thread(WorkerThread, &FuzzQ, &MergeQ));
FuzzQ.Push(Env.CreateNewJob(JobId++));
}
2
3
4
5
6
向下调用, WorkThread函数,其实就是调用了system函数去运行系统命令。
void WorkerThread(JobQueue *FuzzQ, JobQueue *MergeQ) {
while (auto Job = FuzzQ->Pop()) {
// Printf("WorkerThread: job %p\n", Job);
Job->ExitCode = ExecuteCommand(Job->Cmd);
MergeQ->Push(Job);
}
}
int ExecuteCommand(const Command &Cmd) {
std::string CmdLine = Cmd.toString();
// Printf("system: %s\n", CmdLine.c_str());
int exit_code = system(CmdLine.c_str());
if (WIFEXITED(exit_code))
return WEXITSTATUS(exit_code);
return exit_code;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
我们可以增加一个printf并重新编译, 可以看到通过Env.CreateNewJob函数生成出来的job的内容,
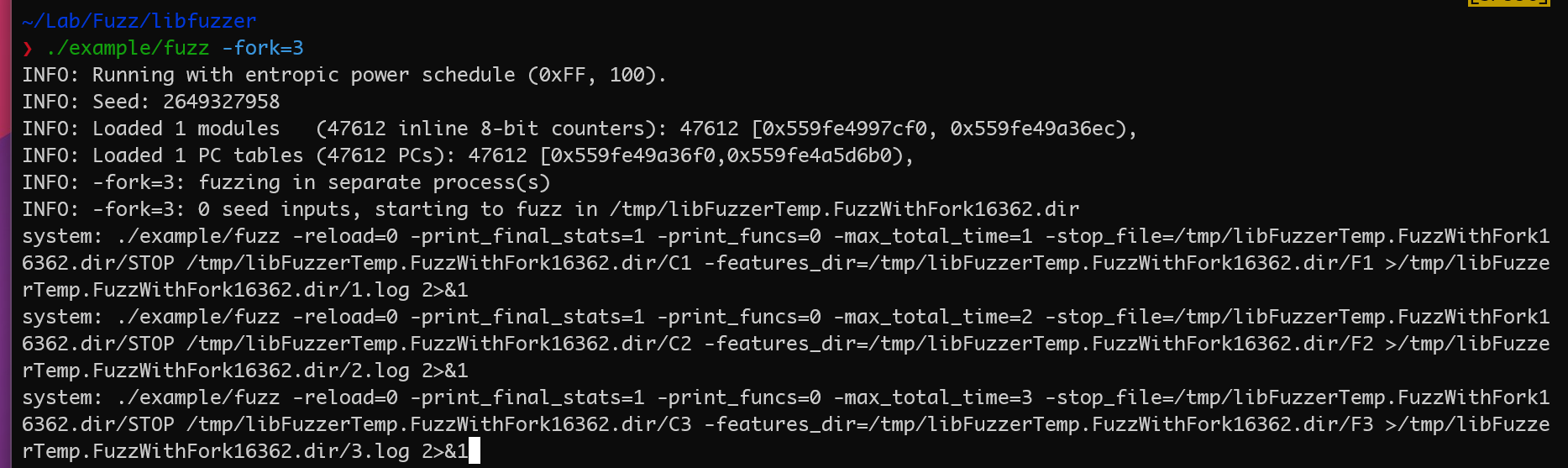
这里其实和WorkerThread函数是对应的,通过Job->ExitCode和MergeQ传递数据。
主要是对于退出状态的处理,如果不是可以退出的状态的话,会继续向FuzzeQ写入Job,让线程继续持续性运行。
while (true) {
std::unique_ptr<FuzzJob> Job(MergeQ.Pop());
if (!Job)
break;
ExitCode = Job->ExitCode;
if (ExitCode == Options.InterruptExitCode) {
Printf("==%lu== libFuzzer: a child was interrupted; exiting\n", GetPid());
StopJobs();
break;
}
Fuzzer::MaybeExitGracefully();
Env.RunOneMergeJob(Job.get());
// Continue if our crash is one of the ignorred ones.
if (Options.IgnoreTimeouts && ExitCode == Options.TimeoutExitCode)
Env.NumTimeouts++;
else if (Options.IgnoreOOMs && ExitCode == Options.OOMExitCode)
Env.NumOOMs++;
else if (ExitCode != 0) {
Env.NumCrashes++;
if (Options.IgnoreCrashes) {
std::ifstream In(Job->LogPath);
std::string Line;
while (std::getline(In, Line, '\n'))
if (Line.find("ERROR:") != Line.npos ||
Line.find("runtime error:") != Line.npos)
Printf("%s\n", Line.c_str());
} else {
// And exit if we don't ignore this crash.
Printf("INFO: log from the inner process:\n%s",
FileToString(Job->LogPath).c_str());
StopJobs();
break;
}
}
// Stop if we are over the time budget.
// This is not precise, since other threads are still running
// and we will wait while joining them.
// We also don't stop instantly: other jobs need to finish.
if (Options.MaxTotalTimeSec > 0 &&
Env.secondsSinceProcessStartUp() >= (size_t)Options.MaxTotalTimeSec) {
Printf("INFO: fuzzed for %zd seconds, wrapping up soon\n",
Env.secondsSinceProcessStartUp());
StopJobs();
break;
}
if (Env.NumRuns >= Options.MaxNumberOfRuns) {
Printf("INFO: fuzzed for %zd iterations, wrapping up soon\n",
Env.NumRuns);
StopJobs();
break;
}
FuzzQ.Push(Env.CreateNewJob(JobId++));
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
最后是回收线程,然后删除临时文件夹。
总感觉这个删除临时文件夹很奇怪,这些运行时的数据应该和种子差不多重要,但是只是在更新种子,没有去保留临时文件夹。而且我遇到了一次第二天运行覆盖率下降了,很奇怪,感觉和这个有关。
# 变异策略
前面提到, 变异控制器初始化实在FuzzerDriver函数,使用直接调用的MutationDispatcher::MutateWithMask和MutationDispatch::Mutate, 着重看一下这三个位置的逻辑。
# MutationDispatcher::MUtationDispatcher
首先初始化,直接设置Rand和Options成员变量。
MutationDispatcher::MutationDispatcher(Random &Rand,
const FuzzingOptions &Options)
: Rand(Rand), Options(Options) {
2
3
然后设置DefaultMutators局部变量。
这里就是libfuzzer内置的12个变异方式和一个按照运行状态决定是否开启的变异。
DefaultMutators.insert(
DefaultMutators.begin(),
{
{&MutationDispatcher::Mutate_EraseBytes, "EraseBytes"},
{&MutationDispatcher::Mutate_InsertByte, "InsertByte"},
{&MutationDispatcher::Mutate_InsertRepeatedBytes,
"InsertRepeatedBytes"},
{&MutationDispatcher::Mutate_ChangeByte, "ChangeByte"},
{&MutationDispatcher::Mutate_ChangeBit, "ChangeBit"},
{&MutationDispatcher::Mutate_ShuffleBytes, "ShuffleBytes"},
{&MutationDispatcher::Mutate_ChangeASCIIInteger, "ChangeASCIIInt"},
{&MutationDispatcher::Mutate_ChangeBinaryInteger, "ChangeBinInt"},
{&MutationDispatcher::Mutate_CopyPart, "CopyPart"},
{&MutationDispatcher::Mutate_CrossOver, "CrossOver"},
{&MutationDispatcher::Mutate_AddWordFromManualDictionary,
"ManualDict"},
{&MutationDispatcher::Mutate_AddWordFromPersistentAutoDictionary,
"PersAutoDict"},
});
if(Options.UseCmp)
DefaultMutators.push_back(
{&MutationDispatcher::Mutate_AddWordFromTORC, "CMP"});
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
接下来是重点位置。
如果用户自定义了变异函数LLVMFuzzerCustomMutator, 那么会直接将Mutators设置为这个函数,如果未设置的话,Mutator=DefaultMutators,
在后续的使用中, 两个变异函数都是直接调用Mutators内的变异函数进行变异,也就是说,这段逻辑是在 使用自定义变异器和使用默认变异器 之间二选一。
最后如果设置LLVMFuzzerCustomCrossOver的话,可以追加上,这个自定义变异可以和默认变异一起使用。
if (EF->LLVMFuzzerCustomMutator)
Mutators.push_back({&MutationDispatcher::Mutate_Custom, "Custom"});
else
Mutators = DefaultMutators;
if (EF->LLVMFuzzerCustomCrossOver)
Mutators.push_back(
{&MutationDispatcher::Mutate_CustomCrossOver, "CustomCrossOver"});
2
3
4
5
6
7
8
libfuzzer的这个位置提供了足够的拓展性, 可以自己实现变异策略, 结构化fuzz实现之一的
libprotobuf-mutator就是实现了一个自定义的变异器,然后和libfuzz组合在一起使用。
跟进一下两个函数, 其实就是稍做检查,然后直接调用EF中对应函数
size_t MutationDispatcher::Mutate_Custom(uint8_t *Data, size_t Size,
size_t MaxSize) {
if (EF->__msan_unpoison)
EF->__msan_unpoison(Data, Size);
if (EF->__msan_unpoison_param)
EF->__msan_unpoison_param(4);
return EF->LLVMFuzzerCustomMutator(Data, Size, MaxSize,
Rand.Rand<unsigned int>());
}
size_t MutationDispatcher::Mutate_CustomCrossOver(uint8_t *Data, size_t Size,
size_t MaxSize) {
if (Size == 0)
return 0;
if (!CrossOverWith) return 0;
const Unit &Other = *CrossOverWith;
if (Other.empty())
return 0;
CustomCrossOverInPlaceHere.resize(MaxSize);
auto &U = CustomCrossOverInPlaceHere;
if (EF->__msan_unpoison) {
EF->__msan_unpoison(Data, Size);
EF->__msan_unpoison(Other.data(), Other.size());
EF->__msan_unpoison(U.data(), U.size());
}
if (EF->__msan_unpoison_param)
EF->__msan_unpoison_param(7);
size_t NewSize = EF->LLVMFuzzerCustomCrossOver(
Data, Size, Other.data(), Other.size(), U.data(), U.size(),
Rand.Rand<unsigned int>());
if (!NewSize)
return 0;
assert(NewSize <= MaxSize && "CustomCrossOver returned overisized unit");
memcpy(Data, U.data(), NewSize);
return NewSize;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
# MutationDispatcher::MutateWithMask
其实还是封装了Mutate, 但是通过参数Mask实现了一个对某些数值的屏蔽,
将屏蔽处理完的数据给Mutate进行变异
// Mask represents the set of Data bytes that are worth mutating.
size_t MutationDispatcher::MutateWithMask(uint8_t *Data, size_t Size,
size_t MaxSize,
const Vector<uint8_t> &Mask) {
size_t MaskedSize = std::min(Size, Mask.size());
// * Copy the worthy bytes into a temporary array T
// * Mutate T
// * Copy T back.
// This is totally unoptimized.
auto &T = MutateWithMaskTemp;
if (T.size() < Size)
T.resize(Size);
size_t OneBits = 0;
for (size_t I = 0; I < MaskedSize; I++)
if (Mask[I])
T[OneBits++] = Data[I];
if (!OneBits) return 0;
assert(!T.empty());
size_t NewSize = Mutate(T.data(), OneBits, OneBits);
assert(NewSize <= OneBits);
(void)NewSize;
// Even if NewSize < OneBits we still use all OneBits bytes.
for (size_t I = 0, J = 0; I < MaskedSize; I++)
if (Mask[I])
Data[I] = T[J++];
return Size;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
# MUtationDispatcher::Mutate
直接封装了MutateImpl, 传入的第四个参数就是我们前面看到的Mutators,
size_t MutationDispatcher::Mutate(uint8_t *Data, size_t Size, size_t MaxSize) {
return MutateImpl(Data, Size, MaxSize, Mutators);
}
2
3
在紧挨着还有个一个对于MutateImpl的封装函数, 是使用的DefaultMutators, 这个函数在libfuzzer中基本没有使用。
size_t MutationDispatcher::DefaultMutate(uint8_t *Data, size_t Size,
size_t MaxSize) {
return MutateImpl(Data, Size, MaxSize, DefaultMutators);
}
2
3
4
这就是我们前面提到的, 变异都是使用的
Mutators, 对于DefaultMutate函数,似乎在配合afl使用的时候会被调用到。
继续向下分析,MutationDispatcher::MutateImpl函数实现也比较简单, 穿工服100次, 通过随机数选择变异方式,然后直接调用,如果设置只能是ASCII字符的话,会进行一次转换,然后变异方式会放入CurrentMutatorSequence,
这个
CurrentMutatorSequence主要的功能 就是打印信息,
// Mutates Data in place, returns new size.
size_t MutationDispatcher::MutateImpl(uint8_t *Data, size_t Size,
size_t MaxSize,
Vector<Mutator> &Mutators) {
assert(MaxSize > 0);
// Some mutations may fail (e.g. can't insert more bytes if Size == MaxSize),
// in which case they will return 0.
// Try several times before returning un-mutated data.
for (int Iter = 0; Iter < 100; Iter++) {
auto M = Mutators[Rand(Mutators.size())];
size_t NewSize = (this->*(M.Fn))(Data, Size, MaxSize);
if (NewSize && NewSize <= MaxSize) {
if (Options.OnlyASCII)
ToASCII(Data, NewSize);
CurrentMutatorSequence.push_back(M);
return NewSize;
}
}
*Data = ' ';
return 1; // Fallback, should not happen frequently.
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 变异方案
相比较于afl 确定性变异的一点点运行和破坏模式的胡乱拼装,libfuzzer显得非常克制。
类似afl的基于默认数据进行的变异, libfuzzer对随机产生的数据也会进行对于原本数据的修改:
EraseBytes: 随机删除某些内容
InsertByte: 向随机位置增加一个随机数据
InsertRepeatedBytes:向随机位置重复增加随机数量的某个随机数
ChangeByte: 随即替换某个byte为随机数
ChangeBit: 随机替换某个Bit为随机数
ShuffleBytes: 通过
std::shuffle在随机一段打乱顺序ChangeASCIIInteger: 在数据中尝试寻找数字的ascii,获取到以后随机进行数字运算,再写入回去。
ChangeBinaryInteger: 随机位置的字节反序, 其实就是调用了
__builtin_bswapxx系列函数。CopyPart: 随机替换或者插入数据自身的一部分。
CrossOver: 这个变异方法拥有一个成员变量
CrossOverWith, 在MutateAndTestOne函数最开始会进行设定,这个变异和CopyPart类似,但是是对于不同样例之间。
然后是基于字典的变异两个:
- AddWordFromManualDictionary: 从用户指定的字典中加入数据,
- AddwordFromPersistentAutoDictionary: 从libfuzzer自动探测到的字典加入数据。
其实上面两者都是调用同样的下层函数, 但是使用的字典不同:
// Dictionary provided by the user via -dict=DICT_FILE.
Dictionary ManualDictionary;
// Persistent dictionary modified by the fuzzer, consists of
// entries that led to successful discoveries in the past mutations.
Dictionary PersistentAutoDictionary;
size_t MutationDispatcher::Mutate_AddWordFromManualDictionary(uint8_t *Data, size_t Size, size_t MaxSize) {
return AddWordFromDictionary(ManualDictionary, Data, Size, MaxSize);
}
size_t MutationDispatcher::Mutate_AddWordFromPersistentAutoDictionary(
uint8_t *Data, size_t Size, size_t MaxSize) {
return AddWordFromDictionary(PersistentAutoDictionary, Data, Size, MaxSize);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# AddWordFromTORC
然后比较有特点的一个变异方案: AddWrodFromTORC
其实仍然是通过字典进行的变异方案,有趣的是这个字典数据来自于 TPC.TORCxx, 这是我们在cmp等位置插桩获取到的数据, 通过 基于这种数据的变异,可以探测到代码层的比较,从而对我们覆盖率影响较大,libfuzzer的变异效果应该会非常不错。
size_t MutationDispatcher::Mutate_AddWordFromTORC(
uint8_t *Data, size_t Size, size_t MaxSize) {
Word W;
DictionaryEntry DE;
switch (Rand(4)) {
case 0: {
auto X = TPC.TORC8.Get(Rand.Rand<size_t>());
DE = MakeDictionaryEntryFromCMP(X.A, X.B, Data, Size);
} break;
case 1: {
auto X = TPC.TORC4.Get(Rand.Rand<size_t>());
if ((X.A >> 16) == 0 && (X.B >> 16) == 0 && Rand.RandBool())
DE = MakeDictionaryEntryFromCMP((uint16_t)X.A, (uint16_t)X.B, Data, Size);
else
DE = MakeDictionaryEntryFromCMP(X.A, X.B, Data, Size);
} break;
case 2: {
auto X = TPC.TORCW.Get(Rand.Rand<size_t>());
DE = MakeDictionaryEntryFromCMP(X.A, X.B, Data, Size);
} break;
case 3: if (Options.UseMemmem) {
auto X = TPC.MMT.Get(Rand.Rand<size_t>());
DE = DictionaryEntry(X);
} break;
default:
assert(0);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
另一个值得注意的是,这个创建的字典,最后会放入CurrentDictionaryEntrySequence
if (!DE.GetW().size()) return 0;
Size = ApplyDictionaryEntry(Data, Size, MaxSize, DE);
if (!Size) return 0;
DictionaryEntry &DERef =
CmpDictionaryEntriesDeque[CmpDictionaryEntriesDequeIdx++ %
kCmpDictionaryEntriesDequeSize];
DERef = DE;
CurrentDictionaryEntrySequence.push_back(&DERef);
return Size;
}
2
3
4
5
6
7
8
9
10
而这个字典的主要作用就是设置PersistentAutoDictionary, 这里和我们前面提到的AddWordFromPersistentAutoDictionary串起来了。
# 插桩策略
# trace方法
前面我们在使用中也看到了需要使用 -fsanitize-coverage=trace-cmp等编译选项设置插桩,但在对应位置插入函数调用以后,函数实现仍然是在libfuzzer中的,在文件FuzzerTracePC.cpp中,
在文件中我们可以看到trace-cmp的实现,所有的比较位置都会被插入这个函数,传入的参数是两个比较的数据,然后继续还有switch div gep的实现,
基本都是先通过__builtin_return_address(0)的封装获取到上层函数地址,然后进入TPC::HandleCmp函数,
template <class T>
ATTRIBUTE_TARGET_POPCNT ALWAYS_INLINE
ATTRIBUTE_NO_SANITIZE_ALL
void TracePC::HandleCmp(uintptr_t PC, T Arg1, T Arg2) {
uint64_t ArgXor = Arg1 ^ Arg2;
if (sizeof(T) == 4)
TORC4.Insert(ArgXor, Arg1, Arg2);
else if (sizeof(T) == 8)
TORC8.Insert(ArgXor, Arg1, Arg2);
uint64_t HammingDistance = Popcountll(ArgXor); // [0,64]
uint64_t AbsoluteDistance = (Arg1 == Arg2 ? 0 : Clzll(Arg1 - Arg2) + 1);
ValueProfileMap.AddValue(PC * 128 + HammingDistance);
ValueProfileMap.AddValue(PC * 128 + 64 + AbsoluteDistance);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
首先获取ArgXor并在TORCx中使用这个当作索引, 获得两个参数,在我们前面提到的变异中也是通过这个成员变量获取的数值。
向后看后续函数定义, 其实libfuzzer还对strcmp、memcpy等进行了hook, 这些内存比较等函数会存放到TORCW成员变量。
对于strstr\memmem这类的内存访问查找,会存放在MMT成员变量。
# 路径记录
# ValueProfileMap
让我们回到 HandleCmp函数, 在后续的ValueProfileMap的设置, 这是关于路径记录的相关设置。
ValueProfileMap.AddValue的实现,可以看出来就是使用某一个bit表示当前的位置,
但是注意这个传入的Value,在TracePc::HandleCmp中可以看到,这个数据是pc和两个参数运算后的结果。
inline bool AddValue(uintptr_t Value) {
uintptr_t Idx = Value % kMapSizeInBits;
uintptr_t WordIdx = Idx / kBitsInWord;
uintptr_t BitIdx = Idx % kBitsInWord;
uintptr_t Old = Map[WordIdx];
uintptr_t New = Old | (1ULL << BitIdx);
Map[WordIdx] = New;
return New != Old;
}
2
3
4
5
6
7
8
9
# ModulePCTable
在开启 -fsanitize-coverage=pc-table以后会创建一个指令表, libfuzzer使用MoudulePCTable来保存这些数据。
ATTRIBUTE_INTERFACE
void __sanitizer_cov_pcs_init(const uintptr_t *pcs_beg,
const uintptr_t *pcs_end) {
fuzzer::TPC.HandlePCsInit(pcs_beg, pcs_end);
}
void TracePC::HandlePCsInit(const uintptr_t *Start, const uintptr_t *Stop) {
const PCTableEntry *B = reinterpret_cast<const PCTableEntry *>(Start);
const PCTableEntry *E = reinterpret_cast<const PCTableEntry *>(Stop);
if (NumPCTables && ModulePCTable[NumPCTables - 1].Start == B) return;
assert(NumPCTables < sizeof(ModulePCTable) / sizeof(ModulePCTable[0]));
ModulePCTable[NumPCTables++] = {B, E};
NumPCsInPCTables += E - B;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
这其中都是指令地址等信息。
# Modules
在开启了-fsanitize-coverage=inline-8bit-counters以后, 会在程序中增加计数器, 在最初的时候需要设置函数在启动时捕获计数器,后续就可以通过计数器判断基本块运行次数了。


TPC中使用Modules表示运行次数,而且和前面提到的ModulePCTable结构对应。
# 判断路径
在Fuzzer::RunOne函数中, 通过ExecuteCallBack运行了样例以后,就是判断的位置,
UniqFeatureSetTmp.clear();
size_t FoundUniqFeaturesOfII = 0;
size_t NumUpdatesBefore = Corpus.NumFeatureUpdates();
TPC.CollectFeatures([&](uint32_t Feature) {
if (Corpus.AddFeature(Feature, static_cast<uint32_t>(Size), Options.Shrink))
UniqFeatureSetTmp.push_back(Feature);
if (Options.Entropic)
Corpus.UpdateFeatureFrequency(II, Feature);
if (Options.ReduceInputs && II && !II->NeverReduce)
if (std::binary_search(II->UniqFeatureSet.begin(),
II->UniqFeatureSet.end(), Feature))
FoundUniqFeaturesOfII++;
});
if (FoundUniqFeatures)
*FoundUniqFeatures = FoundUniqFeaturesOfII;
PrintPulseAndReportSlowInput(Data, Size);
size_t NumNewFeatures = Corpus.NumFeatureUpdates() - NumUpdatesBefore;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
后续这个NumNewFeatures判断是否触发全新路径。
主要函数在TPC.CollectFeatures, 传入的参数是一个匿名函数,在其中会分别便利Modules和ValueProfileMap运行这个匿名函数,
template <class Callback> // void Callback(uint32_t Feature)
ATTRIBUTE_NO_SANITIZE_ADDRESS ATTRIBUTE_NOINLINE size_t
TracePC::CollectFeatures(Callback HandleFeature) const {
auto Handle8bitCounter = [&](size_t FirstFeature,
size_t Idx, uint8_t Counter) {
if (UseCounters)
HandleFeature(static_cast<uint32_t>(FirstFeature + Idx * 8 +
CounterToFeature(Counter)));
else
HandleFeature(static_cast<uint32_t>(FirstFeature + Idx));
};
size_t FirstFeature = 0;
for (size_t i = 0; i < NumModules; i++) {
for (size_t r = 0; r < Modules[i].NumRegions; r++) {
if (!Modules[i].Regions[r].Enabled) continue;
FirstFeature += 8 * ForEachNonZeroByte(Modules[i].Regions[r].Start,
Modules[i].Regions[r].Stop,
FirstFeature, Handle8bitCounter);
}
}
FirstFeature +=
8 * ForEachNonZeroByte(ExtraCountersBegin(), ExtraCountersEnd(),
FirstFeature, Handle8bitCounter);
if (UseValueProfileMask) {
ValueProfileMap.ForEach([&](size_t Idx) {
HandleFeature(static_cast<uint32_t>(FirstFeature + Idx));
});
FirstFeature += ValueProfileMap.SizeInBits();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
# pc_guard
这个方案已经不再使用, 在libfuzzer中可以看到他们运行时会直接警告退出。
void WarnAboutDeprecatedInstrumentation(const char *flag) {
// Use RawPrint because Printf cannot be used on Windows before OutputFile is
// initialized.
RawPrint(flag);
RawPrint(
" is no longer supported by libFuzzer.\n"
"Please either migrate to a compiler that supports -fsanitize=fuzzer\n"
"or use an older version of libFuzzer\n");
exit(1);
}
} // namespace fuzzer
extern "C" {
ATTRIBUTE_INTERFACE
ATTRIBUTE_NO_SANITIZE_ALL
void __sanitizer_cov_trace_pc_guard(uint32_t *Guard) {
fuzzer::WarnAboutDeprecatedInstrumentation(
"-fsanitize-coverage=trace-pc-guard");
}
// Best-effort support for -fsanitize-coverage=trace-pc, which is available
// in both Clang and GCC.
ATTRIBUTE_INTERFACE
ATTRIBUTE_NO_SANITIZE_ALL
void __sanitizer_cov_trace_pc() {
fuzzer::WarnAboutDeprecatedInstrumentation("-fsanitize-coverage=trace-pc");
}
ATTRIBUTE_INTERFACE
void __sanitizer_cov_trace_pc_guard_init(uint32_t *Start, uint32_t *Stop) {
fuzzer::WarnAboutDeprecatedInstrumentation(
"-fsanitize-coverage=trace-pc-guard");
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
应该是这种方法可以通过inline-8bit和cmp实现,而且trace-cmp还可以感知比较数值,写入字典,这对于覆盖率提高有一定增强。