 AFL
AFL
经典的覆盖率导向fuzz,
# 运行策略: 覆盖率导向
# 思路
afl的使用,
首先设置编译器为afl-gcc 进行编译,得到的文件使用afl-fuzz进行fuzz测试。
afl实现思路,
首先载入用户提供的测试用例初始化队列,
开始循环
- 然后从队列中获取下一个输入,
- 进行测试用例的修剪, 在不更改出程序行为的基础上,得到最小用例,
- 使用一系列的变异策略反复变异该文件并进行测试
- 如果存在一些新的路径产生了,那么讲该变异作为输入添加到队列中
# 代码插桩 -标记基本块
对于路径的探索主要的一个点就是在路径变化的时候进行检测,这个检测的实现 就是插桩。
简单来说,就是对每个基本块做一个标记。
首先在使用afl-gcc 只是一个对gcc的封装,进行编译的时候,我们可以通过打印参数看到这一层封装
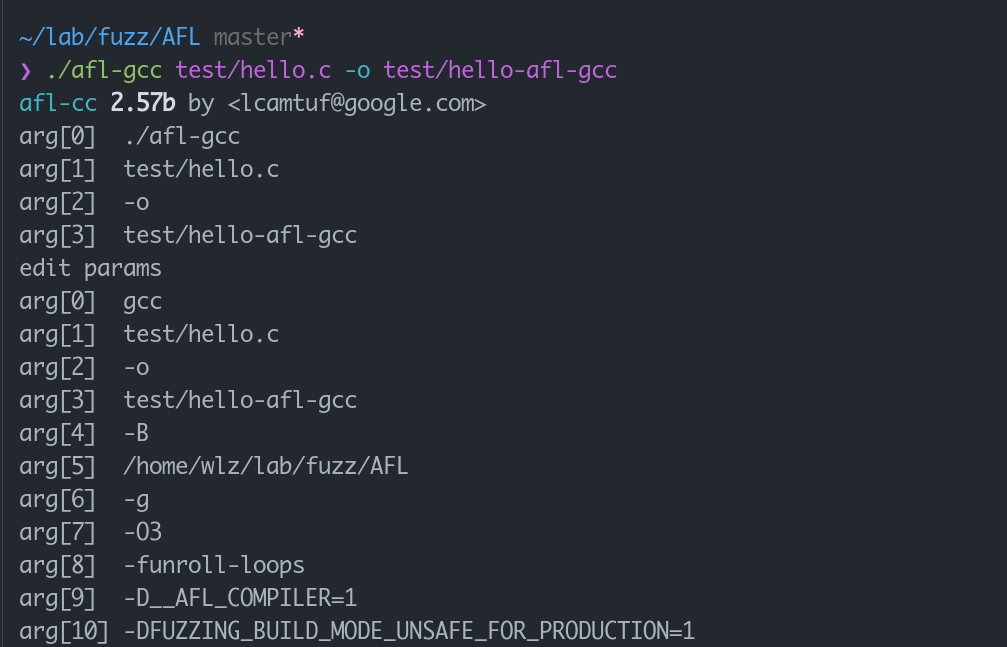
重要的是增加了这个 -B PATH参数,会在gcc编译的时候从这个路径查找需要的文件并运行,也就是我们可以hook某个编译的过程,
gcc编译过程为,
- 预编译, 处理宏等
- 编译, 产生汇编代码
- 汇编, 产生字节码
- 链接, 生成可执行文件
当前目录下,存在一个as的链接文件,

于是这个afl-gcc会转入到这个afl-as进行运行,
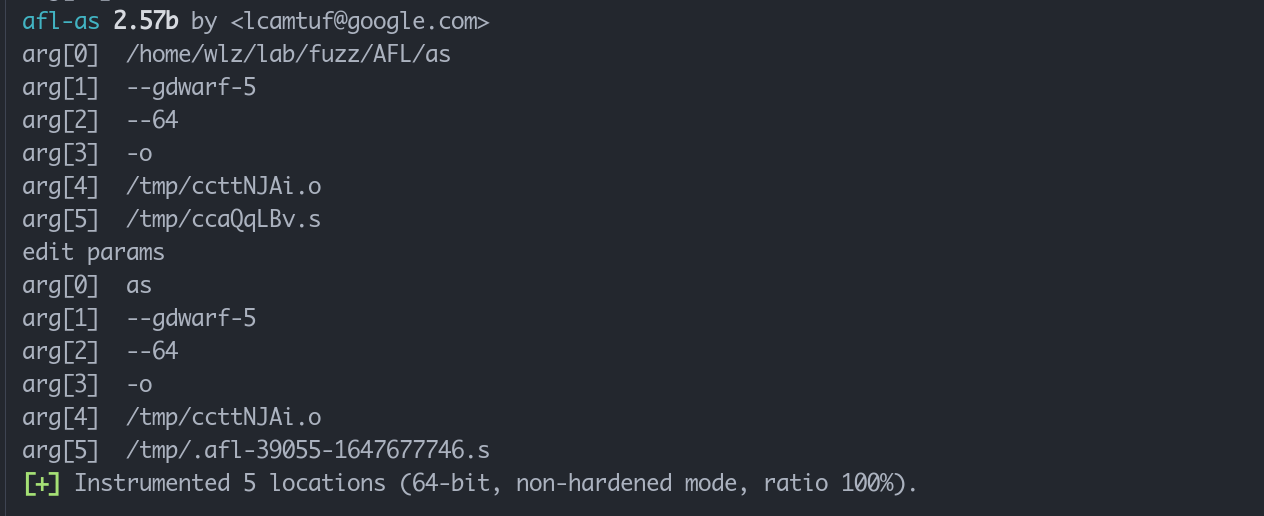
他的参数比较简单,就是封装了一层as, 但是在调用as之前, 对这一段汇编代码, 进行了插桩处理。
可以翻阅 afl-as.c中的add_instrumentation 函数。
基本就是, 在程序开始和程序跳转的位置插入trampoline_fmt_64 并配合产生的随机数表示这个位置。
其实就是通过随机数对每个基本块进行标记,
这个其实也可以通过 llvm进行实现,在
afl/llvm_mode中是llvm的版本,那个也比较简单 实现一个 pass就好。使用gcc进行实现的话,确实只能如此。
那么这个步骤插入的代码如下, 插桩前后对比。
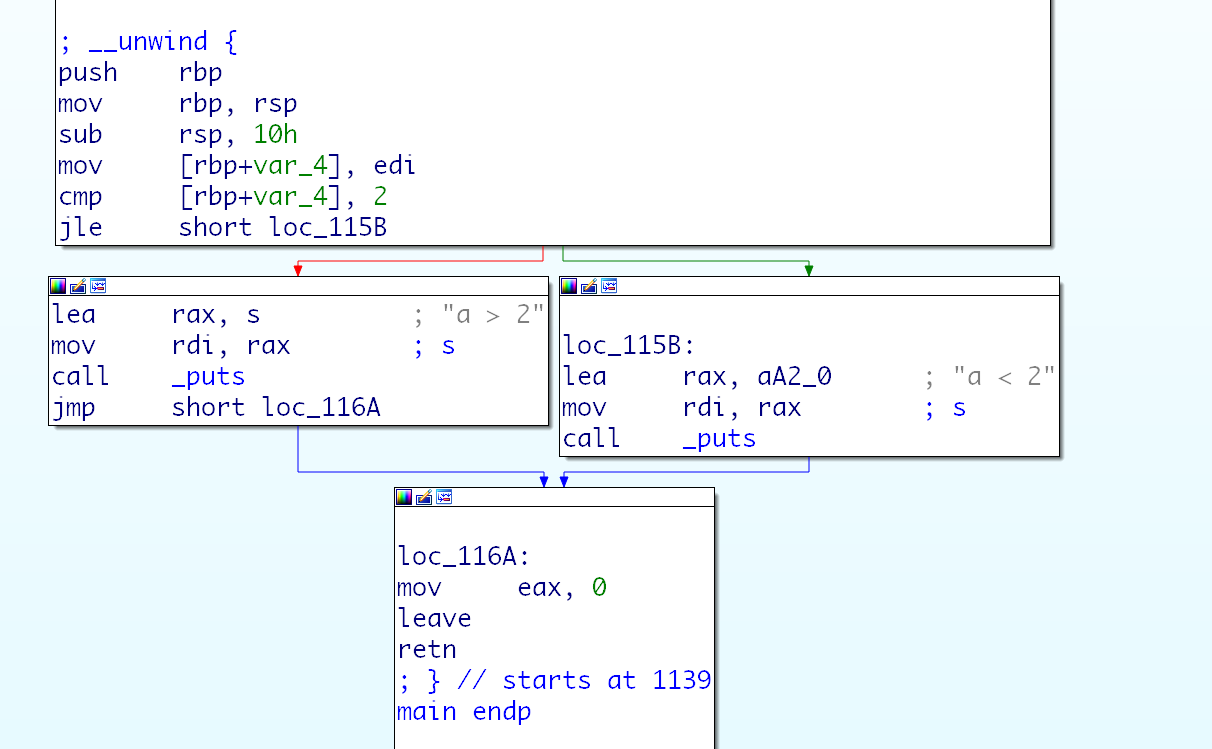
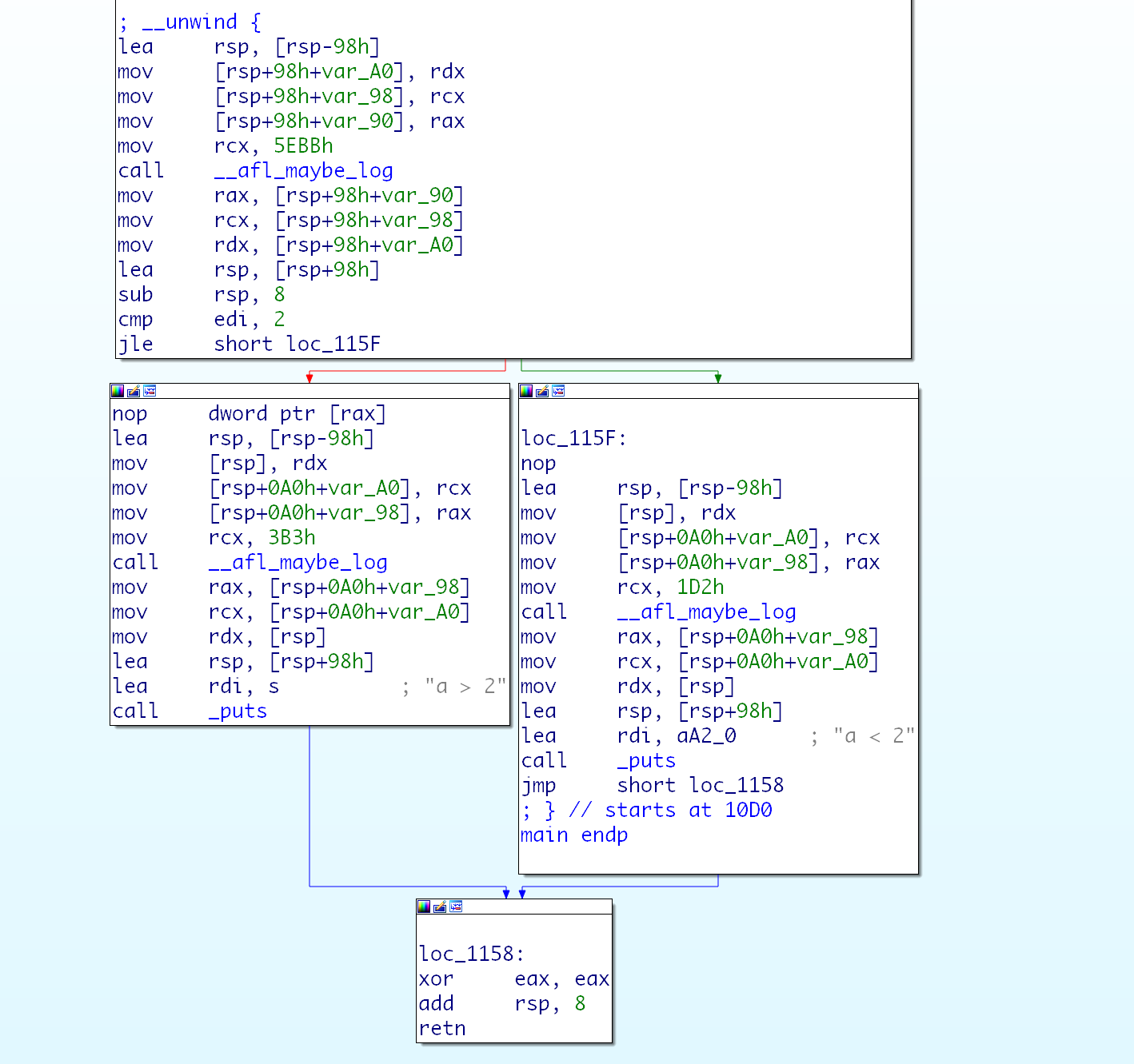
# 路径信息的记录 - 标记路径
其实这个部分,就是在记录流程图中的路径,我们已经可以将基本块表示为对应的数据了,
但是在这里一定是通过 两个基本块来表示从prev -> current的路径,
于是对于路径的记录,afl使用一个 trace_mem[prev_loc ^ current_loc], 表示代码在这个路径上运行的次数,这是一个类似哈希表的思路。
但是这里的prev_loc的更新, 为 prev_loc = current_loc >> 1, 这样可以避免 ^ 运算符的运算交换率和运算表达式相同时结果相同的问题。
也就是我们的每一个记录的路径其实都是一个边, 从上个基本块到下个基本块的连接,因此要保证 a->b 和b->a,a->a和b->b不能相同,也就是我们说的交换率和运算表达式相同结果相同的问题。
通过 prev_loc的更新和亦或运算,可以实现一个 可分辨前后基本块的哈兮算法, 用来表示一个有方向的路径,并如此实现一个哈希表用来表示, 每个路径运行了多少次。
这个trace_mem, 在afl fuzzer代码中是trace_bits, 在插桩的代码中为 _afl_global_area_ptr,
如此就完成了路径信息的记录。
这里其实是我们前面没考虑到的点,我们跟踪的路径信息全部都是来自测试进程,但是路径信息的分析和后续操作都是fuzzer主进程, 因此这里使用进程间通讯或进程间内存共享。afl中实现的做法就是进程间内存共享,使用linux下的 shm。


以上的算法都在函数 __afl_maybe_log 中, 每次运行到一个路径之前都会运行这个函数
前面的插桩就是对每个基本块插入了对这个函数的调用,
这里其实还会面临一个问题,那就是使用hash表的话,肯定会存在一个碰撞概率,afl测试表示这种算法对于碰撞的概率不高, 可以比较稳定的使用。
# 路径信息的分析
先了解afl对于路径的判断,运行某个实例以后,afl如何知道触发了新路径呢?
因为已经通过内存共享同时处理了这块内存,并且通过跳转作为索引进行标记,那么可以直接比较或者hash以后进行比较,这个思路是很简洁流畅的。在具体实现中有一下函数:
# classify_count
我们的路径记录其实重点在于判断是否达到路径, 其次才是运行多少次,
比如说,某次循环,运行一次和两次,其实本身没有什么差别,我们的fuzz不应该认为是一个新的路径,
但是如果是运行一次和运行一万次,还是应该看作不同的,因为一万次甚至不停止 死循环可以判断为dos。
于是afl会在进行计算之前进行一次运算,就将路径处理一下。
处理思路就是在 只记录可达与否和记录运行次数之前取一个妥协, 引入运行次数的范围,某个范围之内,算作同一个数据。范围定义如下
static const u8 count_class_lookup8[256] = {
[0] = 0,
[1] = 1,
[2] = 2,
[3] = 4,
[4 ... 7] = 8,
[8 ... 15] = 16,
[16 ... 31] = 32,
[32 ... 127] = 64,
[128 ... 255] = 128
};
2
3
4
5
6
7
8
9
10
11
实现部分在函数classify_counts
# has_new_bits
测试当前的路径是否产生了新路径。
virgin 一般是传入的virgin_bits, 这个是当前运行的路径表, 如果需要同步则设置bitmap_changed会和out_dir/fuzz_bitmap进行同步,
而current是指向trace_bits, 为刚刚运行过的路径,
这个vir初始化是在函数setup_shm, 将这个内存全部设置为0xff, 而且如果出发了新路径则会运行一句 *virgin &= ~*current;, 于是10翻转,
- 在current中使用1表示路径运行过1次,
- 在vir中使用0表示路径运行过1次,
这种方式非常方便使用了同样的数据意义 表达了 trace_bit表示单次运行,而virgin_bit表示总的运行图,
进行测试,首先判断 current != 0 这个路径运行了, current & virgin != 0,命令中了某个路径或者同一个路径运行的次数不同,
这里需要了解到前面提到的三个点,
- 我们进行记录的信息,在程序内是通过
BYTE形式写入的, 因此每个byte表示一条跳转,- 我们获取到的路径图会通过
classify_count函数进行简化,这个函数设置的几个值在byte范围之内其实都是互相 & 为0的,- 这里的vir和current表示是01相反的,因此这个位置表示的意义是 命中了一个没有运行过的路径或者运行了一个路径没有运行过的次数。
这个就是我们提到的,
trace_bit和virgin_bit相反带来的妙用。
接下来判断的是,cur[0] && vir[0] == 0xff , 将原本的u64分为8个u8进行比较,同时,这个位置的 == 比 &&优先级高, 因此先判断后者,也就是这个判断是判断是否是曾经未运行到的新路径。
因此这个函数的逻辑也比较好理解了。
- 没有路径运行到或者是和上次相同那么返回0,
- 如果运行了某个路径的新的次数那么返回1,
- 如果运行了某个之前没有被运行的路径,那么返回2, 新路径
# fork server
模糊测试这个事情,是在子进程按照传入的测试样例运行afl-gcc编译出来的目标程序, 而fuzz本身是一个父进程, 这里肯定是fork+exec产生的,这一点应该比较简单想到,
但是fuzz中需要不断的创建子进程, 这就导致需要不断的 frok + exec, 其实对于系统 fork一般会有写时复制的优化, 但是对于exec却没办法, 而且exec需要解析elf文件设置相关动态链接库是效率是难以容忍的,
于是afl设计了一个 fork server , fuzzer进程和fork-server通过管道进行通讯,然后fork-server是已经execve以后的测试进程,这个进程一直在死循环中, 通过fuzzer的信号,不断进行fork和获取子进程状态并返回的操作,
# fuzzer
这一部分代码, 在fuzzer,初始化fork-server在函数init_forkserver, 新建测试进程端在函数 run_target
在init_forkserver函数中,最主要的两个点就是创建和设置管道,将 198和199文件描述符作为控制传入端和获取状态,然后就是exec, 然后通过管道数据传输获取到fork-server创建成功,后续就可以正常使用了
然后在run_target函数中,如果不存在fork_server的话,会进入常规的fork-exec的运行路线,
如果存在fork_server, 则直接向控制传入端fsrv_ctl_fd 写入本次的时间(如果超时就会kill掉), 并且在后面等待状态获取端fsrv_st_fd返回状态回来,后续判断本次运行的状态即可。
# fork-server
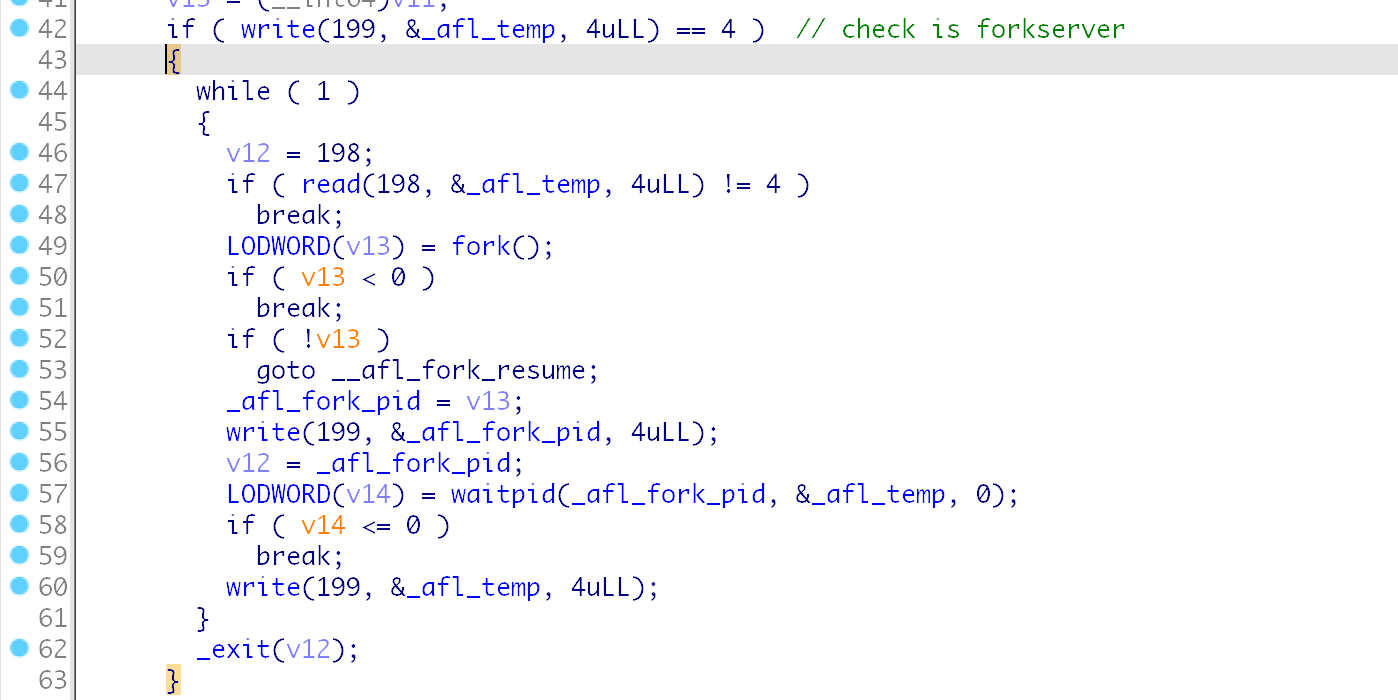
我们再看fork-server这一边,
其实执行这么一套, 对于我们exec出来的fork-server来说,其实我们本身无法改变他的运行起点,肯定是main函数开始运行,这里afl的实现中非常巧妙的将这个fork-server和之前我们提到的__afl_maybe_log 结合在一起,
在这个位置, 可以看到, 一旦进入这个判断,就会一直在这个里面进行死循环,除非发生错误, 这个位置所作的事情也就是我们所说的fork-server的工作,
而进入这个判断,就是从199文件描述符获取数据,在直接运行启动或者fuzzer进行fork-exec启动的时候, 大概率不会存在这么大的一个文件描述符, 因此只会运行常规的路径标记操作,
在fork-server产出新的进程后,也是进入__afl_fork_resume 位置,关闭两个文件描述符,
因此能进入的只有fork-server, 因为只有这时候才会有这个文件描述符,而我们前面提到的主进程也是通过这个写入来判断是否成功创建了fork-server,

# 执行测试
# common_fuzz_stuff
执行测试的函数为 common_fuzz_stuff, 被函数fuzz_one调用, 在每次变异以后都要进行调用,进行测试。
common_fuzz_stuff函数主要逻辑就是调用函数write_to_testcase写入测试文件,然后调用run_target函数运行测试,并返回运行结果,然后调用函数save_if_interesting函数判断是否触发新路径并进行保存。
# run_target
将整个 trace_bits清空, 然后运行程序,这里运行会使用两种方式,直接fork+execve或者使用fork-server, 这就是我们前面提到的方案的使用。
然后获取到程序的返回状态,并检测了程序运行时间,使用classify_counts 对执行的路径进行了简单的分类,然后通过程序返回状态进行状态的返回, 返回以下四种情况:
/* Execution status fault codes */
enum {
/* 00 */ FAULT_NONE,
/* 01 */ FAULT_TMOUT,
/* 02 */ FAULT_CRASH,
/* 03 */ FAULT_ERROR,
/* 04 */ FAULT_NOINST,
/* 05 */ FAULT_NOBITS
};
2
3
4
5
6
7
8
9
10
11
# save_if_interesting
首先调用has_new_bits判断是否有路径不同,如果不存在新路径则直接返回。
值得注意的是,这里路径没有新的话, 仍然会记录崩溃次数,但是不会进行保存,这也是我们在fuzzer中可以看到的,出现了很多crash但是保存的只有一部分的原因。
然后继续的话,肯定是值得记录的crash了, 进行保存之前会调用calibrate_case进行一次校验, 返回结果只用来判断是否为FAULT_ERROR进行报错, 文件会按照对应的格式保存在out_dir/queue里面。
然后根据崩溃原因不同分别放入不同的文件夹内,
- 超时: 如果发现了新的超时路径则保存到
out_dir/hangs/,如果hang_tmout比exec_tmout大的话,那么程序使用hang_tmout重新运行一遍, 如果得到结果是crash则进入crash分组,如果不是的话则返回。 - crash:进行整理,判断是否触发新路径,如果可以的话加入到
out_dir/crash目录。
# 变异策略
这里提到的代码都在fuzz_one函数内。
# 确定性变异
确定性变异是增加对应参数和主fuzz进程会运行的变异。
# bitflip
就是字面意义, 字节翻转从0变成1 1变成0,
运行方案是,先翻转变异,然后运行测试,再翻转回来,也就是整个文件每次只会改变翻转的部分。
一共有六个阶段,
bitflip 1/1 每一个bit进行翻转,
- 这一步会尝试获取token
bitflip 2/1 每两个bit进行翻转
bitflip 4/1 每四个bit进行翻转
bitflip 8/8 每次一个字节进行翻转
- 在进行字节翻转的时候,开始设置 effector map , 记录该字节翻转是否有效 (是否可以产生新路径 ) 并且在之后的其他变异中都会参考 effector map来进行。
bitflip 16/8 每次两个字节进行翻转
bitflip 32/8 每次四个字节进行翻转
比较重要的两个变异,bitflip 1/1和bitflip 8/8, 分别是bit翻转和byte翻转,
# token
在bit翻转时, 会尝试获取token,
具体是,在每次计算路径发现本次和这个测试样例原本的路径不同,会尝试记录对应的数据,当发现和原路径不同,但是连续几个是一样的路径, 那么afl会认为是一个token, 即某些标志位或者校验值,
注意这个检测的次数并不是bit, 而是byte , 通过循环次数进行控制
if (!dumb_mode && (stage_cur & 7) == 7)
并且为了控制token的大小和个数,分别有一下的宏定义。
/* Length limits for auto-detected dictionary tokens: */
#define MIN_AUTO_EXTRA 3
#define MAX_AUTO_EXTRA 32
2
3
4
5
6
# effector map
在进行byte翻转的时候,afl生成 effector map, 标记每个byte的翻转是否有效, 记为0 或 1,
这样的逻辑是, 如果一个byte完全翻转都不能带来路径改变, 那么afl认为这个byte为常规data, 而非某些重要的控制位 的metadata, 对变异来说意义不大, 后续跳过这些无效数据, 可以提高效率。
此外, 当文件有效byte超过EFF_MAX_PERC的时候,会直接将所有的数据全部设置为有效, 这个比例默认是 90%
# arithemetic
arithemetic 也按照处理数据大小分为很多阶段,处理方式就是对数据进行加减操作,
简单的构架如下, 遍历整个输入文件,然后循环运行加减操作,这个加减的上限是ARITH_MAX , 默认值为35.
for (int i=0; i<len-1; i++){
for (int j=0; j<ARITH_MAX; j++){
...
}
2
3
4
5
此外, 通过 effector map和判断此次运算是否和bitflip变异结果相同,可以跳过一些运算,保证效率,
另外, 对于afl还会对大端序和小端序都进行变异。
阶段:
- arith 8/8, 对于每个字节进行变异
- arith 16/8, 对于每两个字节进行变异, 这里会进行大端序和小端序
- arith 32/8, 对于没四个字节进行变异。
# interest
数据替换,就是使用准备好的数据进行替换,
#define INTERESTING_8 \
-128, /* Overflow signed 8-bit when decremented */ \
-1, /* */ \
0, /* */ \
1, /* */ \
16, /* One-off with common buffer size */ \
32, /* One-off with common buffer size */ \
64, /* One-off with common buffer size */ \
100, /* One-off with common buffer size */ \
127 /* Overflow signed 8-bit when incremented */
#define INTERESTING_16 \
-32768, /* Overflow signed 16-bit when decremented */ \
-129, /* Overflow signed 8-bit */ \
128, /* Overflow signed 8-bit */ \
255, /* Overflow unsig 8-bit when incremented */ \
256, /* Overflow unsig 8-bit */ \
512, /* One-off with common buffer size */ \
1000, /* One-off with common buffer size */ \
1024, /* One-off with common buffer size */ \
4096, /* One-off with common buffer size */ \
32767 /* Overflow signed 16-bit when incremented */
#define INTERESTING_32 \
-2147483648LL, /* Overflow signed 32-bit when decremented */ \
-100663046, /* Large negative number (endian-agnostic) */ \
-32769, /* Overflow signed 16-bit */ \
32768, /* Overflow signed 16-bit */ \
65535, /* Overflow unsig 16-bit when incremented */ \
65536, /* Overflow unsig 16 bit */ \
100663045, /* Large positive number (endian-agnostic) */ \
2147483647 /* Overflow signed 32-bit when incremented */
/* Interesting values, as per config.h */
static s8 interesting_8[] = { INTERESTING_8 };
static s16 interesting_16[] = { INTERESTING_8, INTERESTING_16 };
static s32 interesting_32[] = { INTERESTING_8, INTERESTING_16, INTERESTING_32 };
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
然后对运行的数据进行替换即可, 这些数据一般都是临界数据等,有较大概率可以出发整数溢出。
同样,和之前一样,会根据effector map和 判断bitflip arithemetic 是否可达来进行跳过,优化效率。
阶段仍然是,8/8 16/8 32/8
# dictionary full
字典填充,
- user extras over , 从头来是, 将用户提供的token替换到源文件中,
- user extras insert, 从头开始, 将用户提供的token插入到源文件中
- auto extras over, 从头开始,将之前bitflip 过程中识别到的token 替换到源文件中去。
# over token替换
对于user extras over 和 auto extras over的实现确实是类似的, 他们的行都是替换token,
首先,对于out_buf, 使用memcpy从out_buf+i直接覆盖token进去,将token全部替换一遍以后,使用memcpy恢复out_buf, 并增加i, 这样在每个位置都覆盖了token,
另外要注意的是,这样插入token的方案,需要对token的长度进行一次排序,避免需要恢复的情况。
这种插入方案还存在放弃的情况,比如插入后的token和原数据相同,插入的数据量超过长度,插入的位置effector map不存在有效位, 都会放弃此token的插入。
# insert token插入
算法就是设置一个ex_tmp的buf, 然后从ex_tmp+i开始,先复制token, 然后复制out_buf+i, 测试后设置 ex_tmp[i] = out_buf[i], 并增加i, 于是可以在每个位置都插入token进去,
比较重要的一点是,插入token的方案是增加了代码, 所以不需要考虑是否和之前重复以及effector map的问题。
# 随机性变异 havoc 大破坏
所有的fuzzer都会运行的变异。 具体的实现在一个巨大的switch中, 其中的case都是之前提到的变异算法, 但是其中的数据是随机化的, 而且这个switch的分发也是通过随机数进行的, 因此完全成为了一个随机性变异。
其中会发生的变异有16个, 如下:
bit翻转,
设置为随机的interesting value,
- byte大小,
- word大小, 随机选择大小端
- dword大小, 随机选择大小端
选择随机数据进行加法、进行减法,
- byte
- word, 随机大小端
- dword, 随机大小端
随机异或,
随机删除一段数据,
随机选择一个位置插入、覆盖(替换)一段随机长度的数据,
- 这里使用 random%4, 并判断是否为0, 表示一个25%的概率。并由此分出两种变异情况。
- 25%的情况设置为一个随机选择的数据。
- 75%的情况从原文中随机复制一段。
随机选择位置插入、覆盖 token。
# 文件拼接 splice
在文件列表中继续选择文件,并尝试和当前文件进行比对,如果差别比较多的话,会将两个文件进行拼接, 然后继续进入 havoc环节。
# cycle
前面分析的变异策略都是在函数 fuzz_one函数中的,
关于cycle这一部分就是在main函数中了, 在 while(1) 循环中, 挨个选择队列中的文件进入 fuzz_one函数, 当选择完了, 就到了下一次循环的时候了。
# 其他一些重要部分
# afl fuzzer的目录结构:
afl允许多个fuzz一起运行,使用参数 -M 设置为主fuzzer, 使用参数 -S 设置为从fuzzer, 并且后跟id号, 然后对应的fuzz会在 指定的out目录下创建对应的 out/{fuzz_id} 目录, 并且后续需要用到的目录都是在这个目录内的子目录获取和使用的。在默认情况下如果没有指定,那么这个目录将会定名为out/default 。
其中afl fuzzer使用的目录有:
queue目录, fuzzer运行时候我们前面提到按轮次运行,就是这个队列文件为一轮。并且这里面的文件都是按照id:%06u"的开头保存。crashes目录, 可以产生crash的输入文件会收集都在这里。hangs目录.synced目录,只有存在sync_id的时候也就是设置了-S/-M等信息以后才会设置, 这个目录就是用来收集其他fuzzer的文件的。
在afl fuzzer的代码中, 目录相关的全局变量如下:
in_dir, 表示输入样例存放的文件夹,我们在命令行参数 -i 指定的。out_dir, 表示输出文件夹,我们在命令行通过 -o 参数指定的。sync_dir, 表示同步文件夹,- 如果指定了sync_id的话,才会使用这个文件夹,用于多个fuzzer共享,
- 并且这时会调用函数
fix_up_sync, 设置sync_dir=outdir,out_dir = out_dir/sync_id,
# sync_fuzzer 多fuzzer协作
这个函数的作用就是获取其他fuzzer的case, 寻找有趣的一些case并尝试运行。 了解了fuzzer的目录结构就好理解多了。
首先打开sync_dir文件夹,循环读取其中的文件,获取文件名,如果不是.开头 并和我们的sync_id相同的(我们自身的out_dir)的话, 也就是其他的fuzzer的out_dir, 那么打开它,并且读取对应的queue文件夹。
如果内存不大的话, 会导入到内存中,然后通过run_target函数运行,并通过save_if_interesting函数决定是否保存,
因为fuzzer中的文件也按照id保存,因此还会维护output/.synced文件夹,里面对应fuzzer的sync_id为文件名的文件,其内容保存在对应的fuzzer中测试的最后一个文件的id, 这样可以保证不重复运行。
# 语料修剪 trim_case
语料修剪在每次fuzz_one函数开始时运行,进行修剪,得到可保持原执行状态的最小文件,然后再开始进行变异。
其实思路也还比较简单,就是直接跑,然后一直尝试修剪并运行,最后得到一个可以保证正常运行得到路径不变的最小长度,
通过 run_target函数运行测试样例, 然后通过hash32 得到运行路径的哈兮,用于判断是否路径变化,
如果确实存在更小的路径会设置needs_write标志,在后续进行文件重新写入。