 SSA简述
SSA简述
在最近一段工作,在Yaklang.io做一些基于SSA格式中间代码的分析工作。这篇是在前期调研时的内部分享。简单的介绍了SSA格式的特点、好处以及其构建思路。
# SSA 在编译过程中的位置
# 介绍
编译领域的整体介绍。 编译问题根本上说,是一个从一个语言转换为同等语义的另一个语言的过程。在计算机领域中,我们期望的是编程语言可以越来越符合人类的理解,而机器可理解可运行的是最底层类汇编的语言(其实最后跑的都是数字,汇编都是对应出来的符号标记给人看的),因此计算机领域中的编译问题基本上是高级语言到低级语言的编译。
在最开始 1.0 时代,重点在于如何实现一个高级语言到低级语言的转换,这里开始研究词法、语法、语义等内容,这都属于编译前端,也是各类教材最多的内容。 在 2.0 时代,可以完成转换以后,重点转向了如何生成高效的代码,这里的重点转向中后端,代码消除、循环优化、指令调度、异构目标优化等问题被提出。在这个时期 LLVM 凭借模块化的设计给编译的中端后端提供了一个良好实施平台。
在 3.0 时期,由于 LLVM 设计的前中后转换,编译问题进一步被抽象为多前端到多后端的转换问题,并被应用在其他领域,比如 Ai 的部署问题和 HPC 等领域。同时由于编译中端蕴藏的信息极大,也开始使用在语言支持、代码格式化、静态代码审计等方向。
前端的重点在于源代码的解析和语法树的构建。 中端的重点在于对 IR 的处理。 后端的重点在于体系结构领域。
# 专有名词
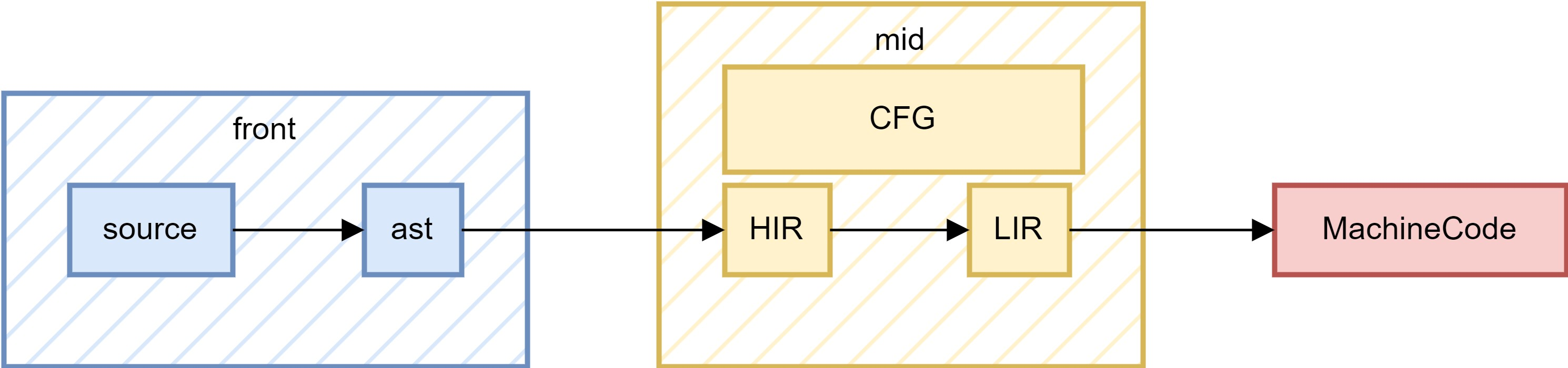
# 语法阶段
词法语法分析:按照预定义的语法规则解析输入的字符流,得到其对应的语法树。
从某种角度来看,源代码其实只是按照语法规则编写的字符流,其中依靠语法规则表达的,是程序的语义,这个语义,由数据的处理(数据流)、程序的运行逻辑 (控制流)、作用域、类型系统、函数调用组成。 这是因为编译就是保持语义一致的语言转换过程。 这些关键信息将会贯穿整个编译的过程,即使是最后生成的机器代码也会隐含。 甚至从机器代码入手进行处理都应该是可行的。这只是复杂程度的问题。当然除此之外的其他很多信息将会在编译的流程一步步丢弃。
Ast:抽象语法树,从源码解析得到的,具有非常多语法特征的数据结构,一般定义为树或者图。表示程序的语法结构和表达式。 比如我们可以在 ast 中识别到 if、loop 语法树节点就可以知道这是一个判断或循环,但是在后续的 cfg 中我们只能通过分支和回环来判断。 得到 ast,是从字符串流进行语义处理的第一步,这里获取到的混合特定的语言语法特征的信息需要进一步的处理和分离。
Javac 的数据处理在 ast 遍历里通过一堆成员跟踪分析的状态,一遍 ast 遍历得到数据。
# CFG
控制流是指程序中各个基本块之间的执行顺序和条件关系,描述程序中语句和表达式的执行顺序。控制流分为两种基本类型,顺序控制流和分支控制流,分支控制流分为条件分枝和循环分支。在编译其中,可以通过 cfg 进行对控制流的表达,其中的基本快表示顺序控制流,控制流边表示分支控制流,组合形成一个有向图。
Cfg:控制流图,表达程序的控制流,其中的每一个节点为一个基本块,表达一个顺序控制流,每一条边为控制流边,表达分支控制流。CFG 表达的重点是程序的控制流关系。在实现上,cfg 内的每个 block 会指向自己的前序基本快和后续基本快。
需要注意,cfg 其实并不在一其中的顺序执行的具体指令。因此一般情况下会将 IR 套在这里头
# IR
IR: 中间表示,为了前后端的分离而引入。 一般情况下,IR 通过定义的指令集表达数据流和控制流关系,其中跳转相关的控制流语句将会抽象为 cfg 的控制流边,进而将 cfg 和 IR 整合在一起。
# 格式
IR 本身的特征,主要有两种:
- TAC 三地址码格式,可以方便从 ast 生成以及向后端机器代码生成,TAC 表达的是简单的指令间关系。对于值和变量的数据并不在意。
- SSA 静态单一赋值格式,可以方便的进行数据流分析,SSA 表达的重点在于数据间关系。
x = 1
y = x + 2
x = y + x
2
3
对于上述的例子,两种形式将会产生以下两种 IR:
# tac
x = 1
y = x + 2
x = y + x
# ssa
x = 1
y = x + 2
x2 = y + x
2
3
4
5
6
7
8
- Dense 分析:要用个容器携带所有变量的信息去遍历所有指令,即便某条指令不关心的变量信息也要携带过去。这是使用 TAC 进行数据流分析时候必须进行的。
- Sparse 分析:变量的信息直接在 def 与 use 之间传播,中间不需要遍历其它不相关的指令。在进行数据流分析的时候可以直接通过 use-def 获取,可能还会存在循环问题,但是不会遍历不相关指令。
IR 也不只是只有这些,只不过这两种在编译器领域使用最为常见,在以前是 TAC 格式常见,开始优化以后 SSA 的格式基本成为各种编译器的默认 IR 设计格式。 IR 种类很多,在定义上,字节码也属于一种 IR,被称为 stack-based IR。
# 多维度
需要注意,IR 的设计是多维度的, 主要体现在以下两个点:
- 在编译顺序中,可能一个语言将会使用多种 IR 进行一层层的处理,
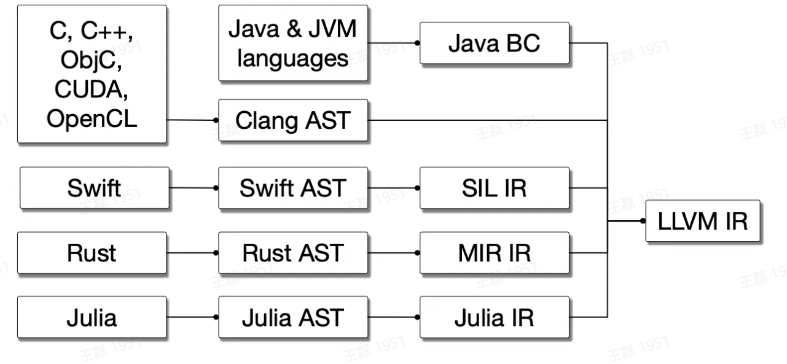
TinyGo 很好的表达了一个中级 SSA 形式的 IR (GoSSA)向低级 SSA 形式 IR (LLVM-IR)转移的过程。
MLIR 项目的设计目标之一也是为了统一高级 IR。如下图所示,多种语言都会使用自己的语言特定高级 IR 进行语言特定的优化,然后向 LLVMIR 转换并接入 LLVM。
- 对于任意一个 IR 本身而言,一般也会设计: 运行时、可阅读、序列化三类 IR 的具体表示。 LLVM 对于 IR 的设计就分为这三类,
- 通过 C++的 class 定义运行时的 IR 对象,提供各种方法用于生成 IR 或对 IR 进行优化,
- LLVM 内还有针对序列化的 IR 字节码 (被称为 bytecode)的序列化反序列化处理,
- LLVM 还编写了简单的对于可阅读的 LLVM 类汇编的 IR 的解析器,从文本格式的可阅读的类汇编 IR 生成 IR 对象。
# SSA 是什么
In compiler design, static single assignment form (often abbreviated as SSA form or simply SSA) is a property of an intermediate representation (IR), which requIRes that each variable is assigned exactly once, and every variable is defined before it is used. -- from wiki
SSA 形式的 IR 主要特征是每个变量只赋值一次。 当出现重复赋值的时候,将会定义一个新的数值表示。
示例:
a = 11
b = a + 2
a = a + b
2
3
SSA 形式的 IR 如下:
a = 11
b = a + 2
a.1 = a + b
2
3
对于 SSA 格式而言,顺序流程可以直接通过新定义进行处理。但是当出现判断或循环就会出现问题。
# 数据流的合并
本质上来说,SSA 格式转换比较需要注意的问题就是数据流的合并问题。 比如有以下的代码,其中 a 表示为 b 和 c 中较大的一个数。 这时候 a 的值可能会是 b 也可能会是 c。这就是一个数据流合并的时候。
a = if(b > c) {
b
} else {
c
}
2
3
4
5
# Phi
SSA 格式提出 Phi 函数 (phi 指令),
<result> = phi [<val0>, <label0>],.....
Phi 指令包含多个参数,每个参数是一个参数 val 0 和基本快标签 label 0,表示如果从基本快 label 0 来到这个基本快,phi 指令的返回值为 val 0。
而且 phi 指令参数的个数必须和该基本快的前序节点格式一致。
前面的例子,通过下面一个简化的 SSA 表示:从 then 基本块到 end 基本块则 a =b,从 else 基本块到 end 基本块则 a = c,表示为 a = phi(b, then; c,else)
cmp b,c
jne else
then:
b
jmp end
else:
c
end:
a = phi(b, then; c, else)
2
3
4
5
6
7
8
9
这是一个非常经典的做法,大多数的 IR 实现都会使用 Phi 指令的形式实现 SSA 格式 IR。
# Block argument
设置基本块的参数,跳转向基本块的时候传入这个参数,在基本块内将会直接使用这个参数数据,比如以下的示例表示之前的例子,在 end 基本块拥有参数 a,在 then 基本块中跳转的时候传入参数为 b,则到达 end 基本快的时候 a=b,在 end 基本块跳转的时候传入参数 c,则到达 end 基本快的时候 a=c。同样实现了数据流合并的操作。
cmp b, c
jne else
then:
jmp end(b)
else:
jmp end(c)
end(a):
a
2
3
4
5
6
7
8
Ref: SSA 形式的设计取舍: Phi 函数的新形式? - Max's Zone (opens new window) 由 chris lattner 设计的一种新方案,主要是为了去除掉显示的 phi 指令,因为 phi 对于 ssa 的处理会增加额外工作量以及潜在的 bug。主要是在 chIRs lattner 的 swift 和 MLIR 两个项目中被使用。MLIR Rationale - MLIR (opens new window)
这样的设计其实对于优化来说更有意义,因为不需要考虑每个 block 中的 phi 指令的特殊处理,而且其实 phi 指令转换为机器码的时候会使用类似的方案转换为汇编: Phi node 是如何实现它的功能的? - 知乎 (opens new window)
但是对于数据流的分析,原本可以使用 phi 指令进行前序基本快的数据流聚合,这样在数据中可以直接获取,通过 block-argument,将会将基本块分割开,如果没有保留参数的 use-def 的话将会失去这个特点,会将数据流混合在控制流里头。
而且 MLIR 里应该是并没有保留 block-argument 的数据流的,因此对于 MLIR 的数据流分析仍然需要通过传统方案进行不动点求解。 参数这样的设计思路的话也确实不应该向前保存数据流。参考: Understanding the IR Structure - MLIR (opens new window):MLIR 的 use-def 链的定义会来自于指令的返回或基本快参数,表示该数据流以基本快内为单位。 Writing DataFlow Analyses in MLIR - MLIR (opens new window) MLIR 的数据流分析。
# SSA 带来的好处
主要是在数据流分析过程中,明确的单定义结构建立 use-def 非常方便,甚至在构建 ssa 的时候可以将 use-def 链直接保留在 ssa 结构内。
过程间和过程内的数据流分析算法在类似LLVM的IR或HotSpot C1的HIR中,是如何实现的? - 知乎 (opens new window)
怎么利用LLVM IR和LLVM的api来实现诸如活跃变量分析等这样的数据流分析算法? - 知乎 (opens new window)
# 相关项目
# TinyGo
Site Unreachable (opens new window) 一个接入 LLVM 的 golang 语言实现,使用 golang 编写。 基本上语言语法词法分析、语法树、SSA 全部都是用的 golang\tool 里头提供的,主要做的工作在 golang-SSA 到 LLVM 的翻译。 build.go (opens new window) compiler.go (opens new window)
有一个注意点:tinygo 提供了一套比较完整的使用 cgo 包装的 LLVM: go-LLVM。 系统有下载的 LLVM 可以直接使用
-tags=LLVM16这样的方式指定。他使用 go build comment 的方案:LLVM_config_linux_LLVM16.go (opens new window) 。 同时 tinygo 项目本身的 gomod 里头写的 go-LLVM 版本太低了得手动升级一下 go.mod (opens new window)
# 如何构建 SSA 格式的 IR
需要处理数据流的交汇问题,以此保证数据赋值的单一性。无论是使用 block-argument 还是 phi 指令,都需要找到数据流交汇点,这才是难点。
# 通过 Load-Store 的方式作弊
LLVM 中为了前端生成 SSA 格式的 LLVMIR,使用 store 和 load 开了一个后门,通过这两个指令设置的内存不受 ssa 格式影响,因此可以简单的将多次赋值的指令全部处理为内存,转入 LLVM-IR 以后将会有一个特殊的 pass 进行 memory 2 reg 操作,将内存操作转换为虚拟寄存器和 phi 指令的使用。 这个方式其实是直接回避了数据流合并的问题,通过内存开了个口子,还是使用的重复赋值数据。但是实现及其简单。
cmp b, c
pa = alloc(i32)
jg else
then:
store b, pa
jmp end
else:
store c, pa
end:
a = load(pa)
2
3
4
5
6
7
8
9
10
[[#YuLang]]
剩下两种分析方案,不管是 cfg 还是 ast 入手去生成 ssa,其实都是期望通过对于控制流合并点和变量定义的筛选,找到数据流合并点,数据流合并点才是真正需要插入 phi 值的时候。 和 LLVM 先转成用内存作弊的 IR 然后进行转换类似,很多构建方案将会创建过多的 phi 指令,然后再通过后续的优化进行精简。
# 基于 cfg 求解支配边界构造: 算法 Cytron 1991
因为 ast 到 ssa-cfg 之间其实隔了两层,cfg 需要控制流的分析,ssa 需要数据流的分析。对于 cfg 的分析更为简单,一般会先构建 cfg,然后对 cfg 进行分析,分析的对象是 cfg 中的节点,也就是基本快。最后得到的结果也是需要在哪些基本快中插入 phi 指令。 其实对 cfg 分析,还是对于控制流的分析,通过这个分析得到控制流的交汇点,如果交汇点的两个前序中定义了某个变量,则可以认为这两个前序节点中的某个变量定义不同,这个控制流的交汇点就是数据流的交汇点,可以直接插入 phi 指令。 在很多算法中,可以插入过量的 phi 节点以保证 SSA 格式的正确,然后通过后续的优化进行处理去除多余的 phi。 LLVM 的构建方案使用 Cytron 1991 算法。
参考:
LLVM SSA 介绍_Enorsee的博客-CSDN博客 (opens new window) 如何构建SSA形式的CFG | 山楂片的博客 (opens new window)
论文: https://www.cs.utexas.edu/~pingali/CS380C/2010/papers/ssaCytron.pdf (opens new window)
# 基于 ast 构造: 论文 Braun 13
其实评估的仍然是 cfg 中的规则,但是认为输入是 ast ,其中可以表达控制流结构,则可以在不断生成 cfg 的同时通过一定的算法处理分支合并语句生成 ssa。
参考:
有没有可能直接遍历AST生成SSA形式的中间代码,而不是先生成quad四元式,再转换为SSA形式? - 知乎 (opens new window)
如何使用AST生成程序的控制流图(CFG)? - 知乎 (opens new window)
论文: https://pp.info.uni-karlsruhe.de/uploads/publikationen/braun13cc.pdf (opens new window)
项目: [[#DCC]]
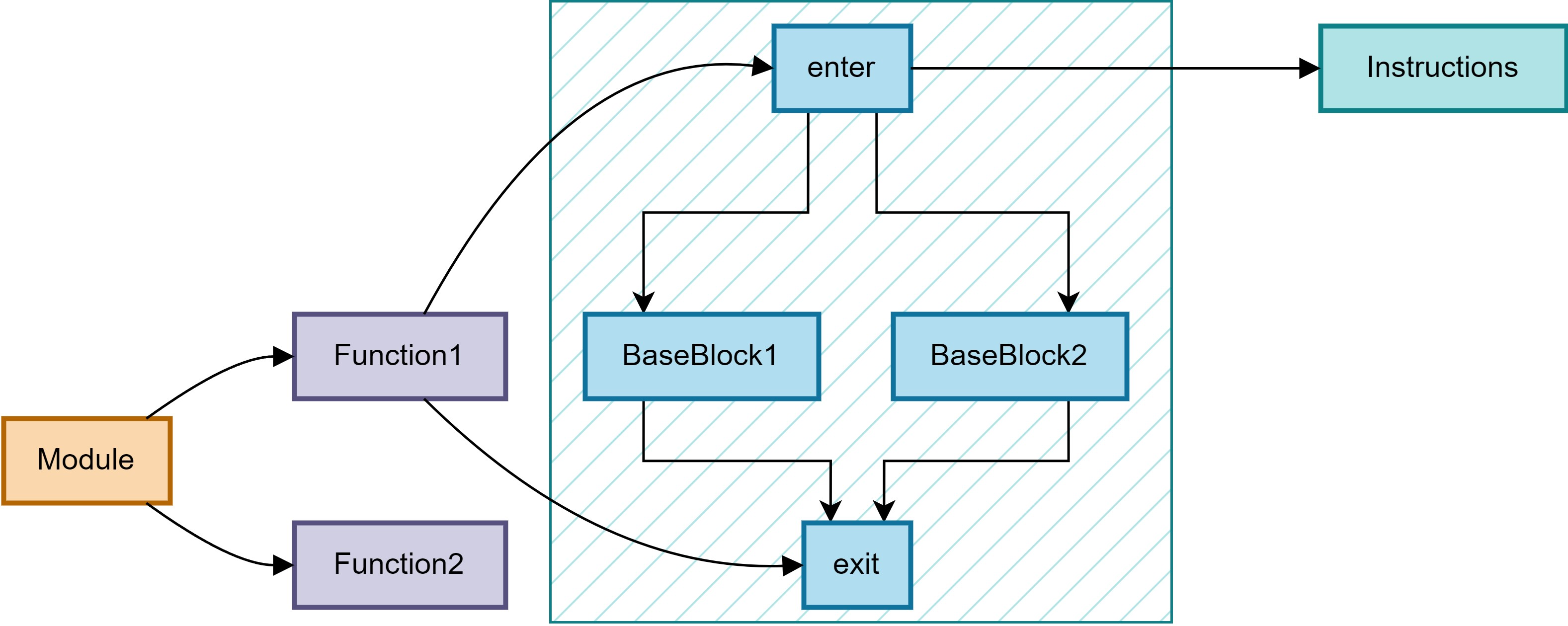
# CFG 设计
一般的语言中端设计方案: CFG+SSA 的结构。 一般的整个程序表示为一个 Module,其中包含多个 Function,每个 Function 内含多个 BaseBlocks 的列表,这些 BaseBlock 本身是图的一个个节点,内部保存自身的前序和后继节点,在示例中我们画出了这样一个图。 特殊的两个 block 是 enter 和 exit 被 function 直接指向表示函数入口和出口。 每个 block 内含多条 Instruction 表示指令,这些指令都是遵守 SSA 形式的。 通过这样的 CFG 设计可以表达程序的控制流。
对于数据流的表达是通过这些 SSA 形式的 Instruction 表达的,在后文将会讲解。
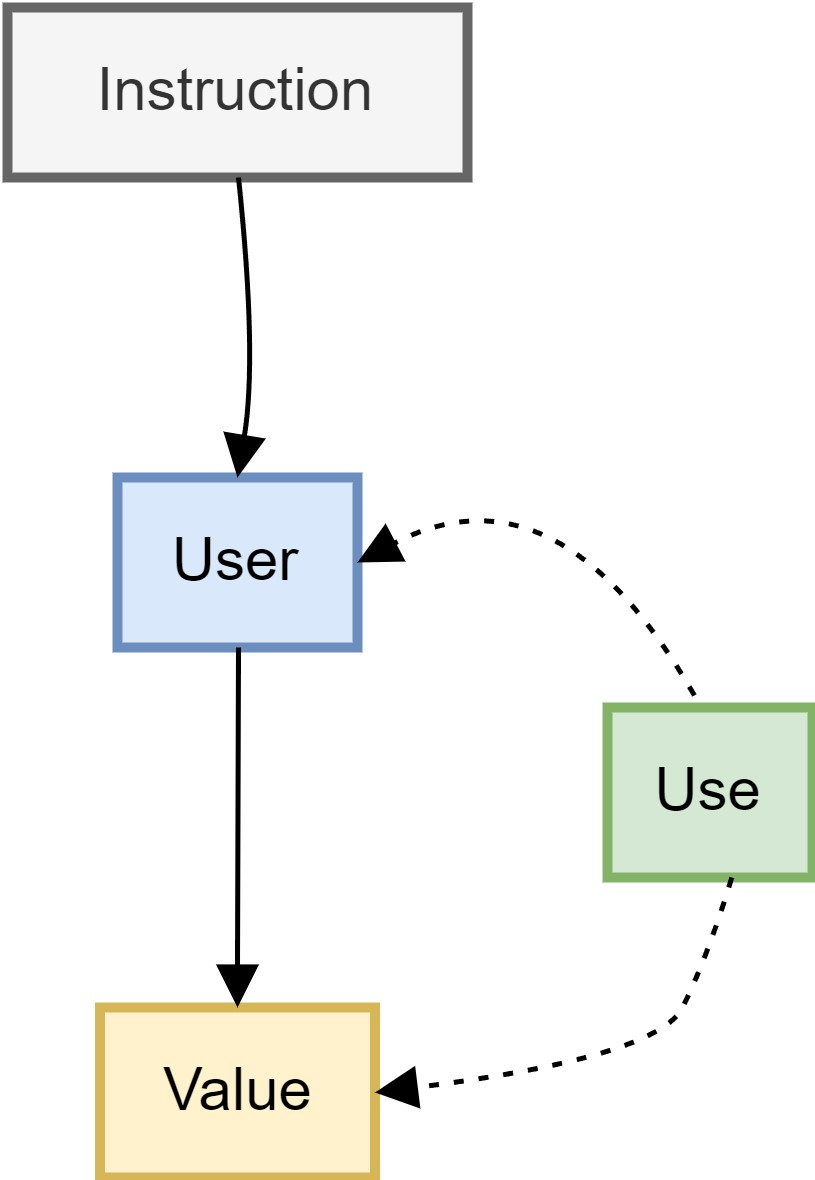
# Use-def 链设计
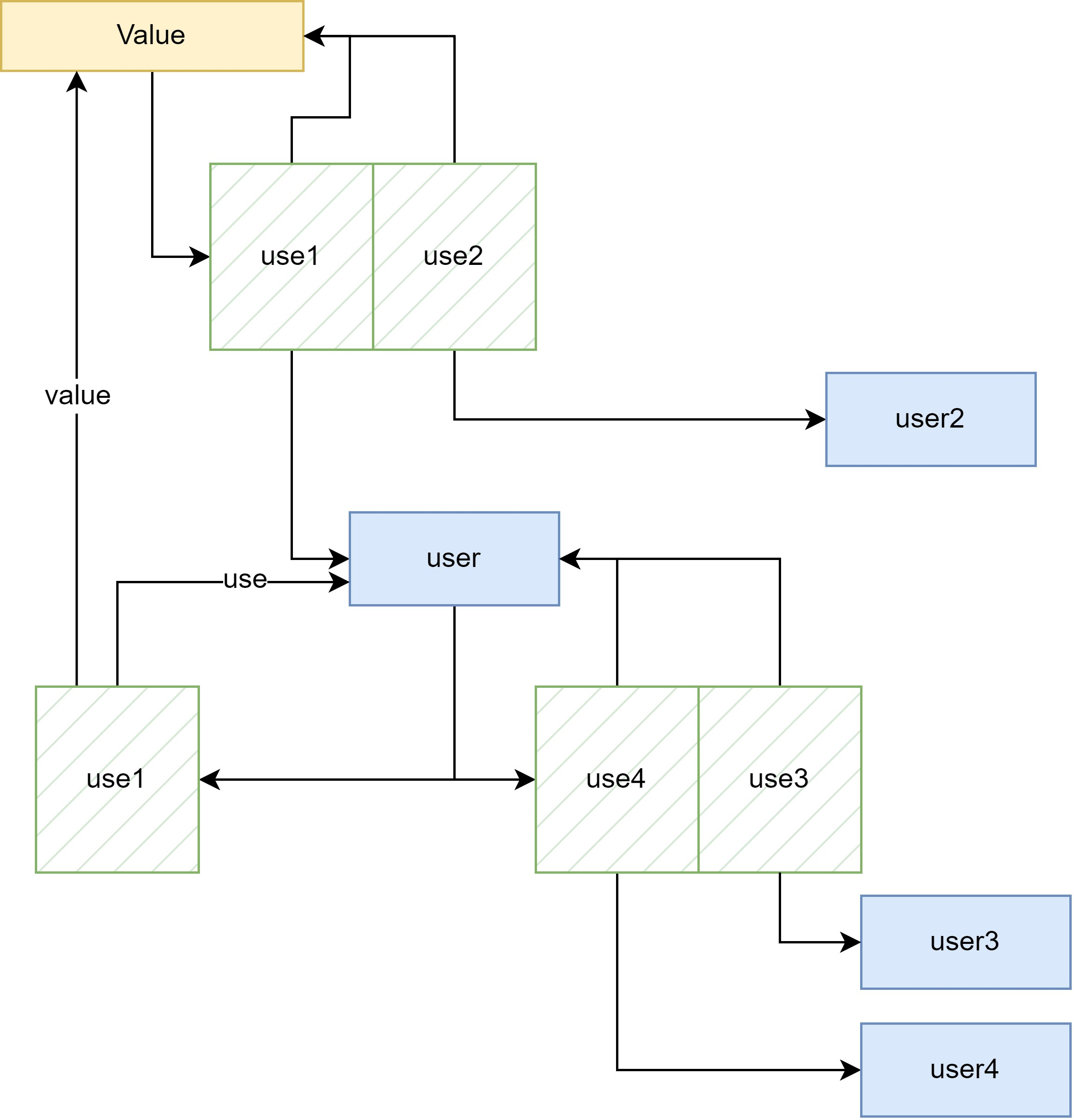
基础结构定义如下。所有的 value 是可以被使用的变量,user 表示可以使用其他值,而且 user 继承自 value,每个 user 同时作为 value 也可以被其他的 value 使用,还有 use 结构, use 存在两个指针分别指向 user 和 value,表示一个 user 正在使用一个 value。
运行时数据排布如下, 每个 value 保存 use 列表,其中表示哪些 user 使用了自己,比如 (user 1 user 2) 而 user 保留两个 use 列表,
- 其中一个表示自己在使用哪些 value,比如 (user 1)
- 另一个表示哪些 user 在使用自己。比如 (user 3 user 4 )
LLVM 架构中最重要的概念,以及编译器设计的提示 · GitBook (opens new window)
# Sea of nodes
这是另一套 如何理解v8的sea of nodes IR设计,能否推荐一些paper阅读? - 知乎 (opens new window) Sea of node 的设计主要使用在 java 和 javascript 中,主要由 cliff click 大神的两篇论文提出:
- From Quads to Graphs
- A Simple Graph-Based Intermediate Representation
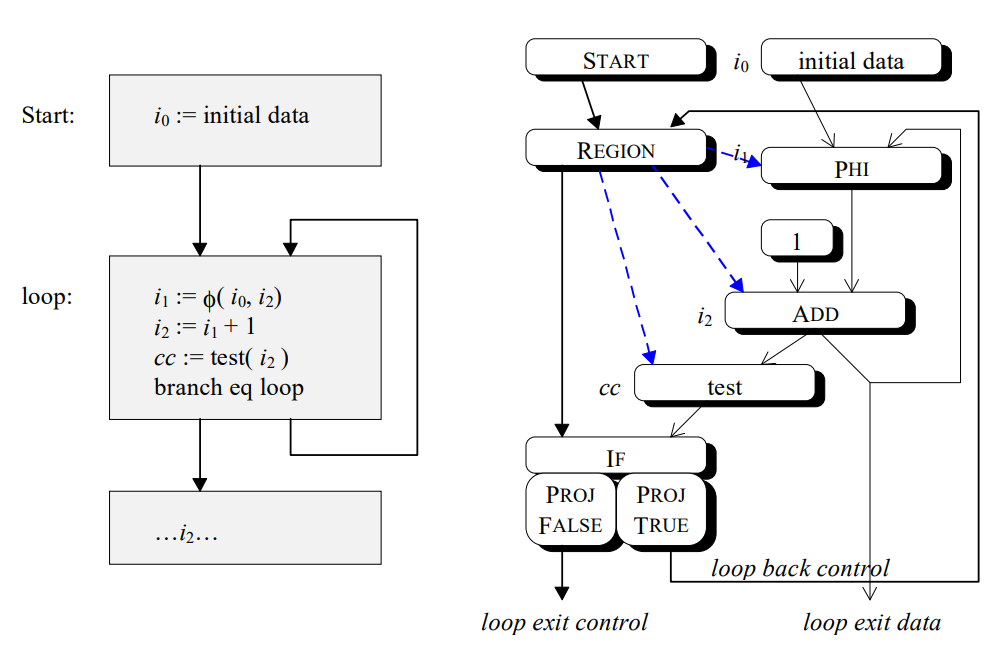
其主要的想法是将能分析的数据都分析出来,通过 Region 节点表达控制流,通过指令运算节点表达数据流。
一个示例如下,左图表示传统的 CFG+SSA 图的模式,右图表达对应逻辑在 sea of node 形式 IR 下的表达。
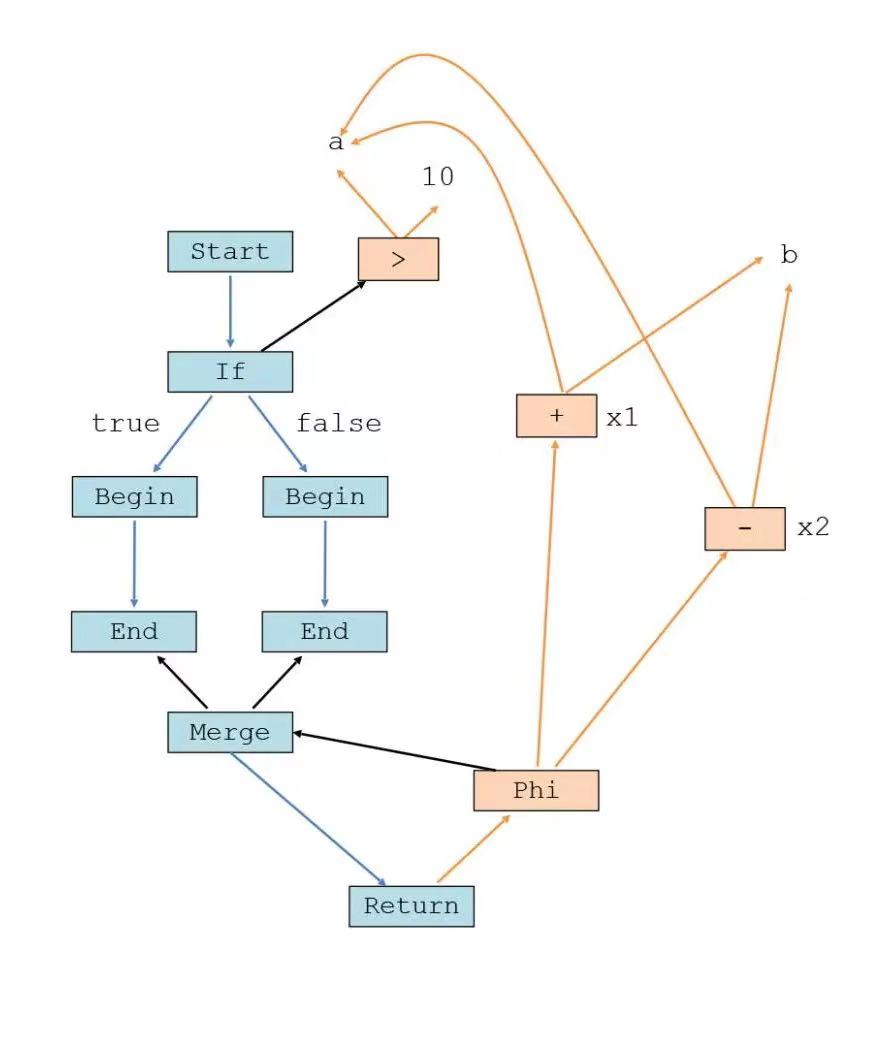
 Sea of node 的优势在于可以非常好的将数据流和控制流分离开,并且显示的表达这个控制流和数据流,而不是通过 CFG+userdef 两个图嵌套在一起的形式去表达。
一个数据流和控制流的关系如下图所示。
Sea of node 的优势在于可以非常好的将数据流和控制流分离开,并且显示的表达这个控制流和数据流,而不是通过 CFG+userdef 两个图嵌套在一起的形式去表达。
一个数据流和控制流的关系如下图所示。
# 相关项目
# YuLang
GitHub - MaxXSoft/YuLang: The Yu (羽) programming language. (opens new window) 一个比较完整实现的语言,前端完成了 ast 的构建,中端完成了 ssa 格式的转换以及 pass 构架和两个 pass 的编写,后端接入 LLVM 编译得到目标文件。使用 cpp 编写。
唯一的不足可能是只生成了 obj 文件,而语言标准库的 import 只显示为外部引用包,需要再手动依赖 clang 的连接器,将多个 object 和 archive 文件进行链接。
这个设计没啥大问题,但是可以整合在一起的感觉。
Ssa 的设计:全部变量通过 store+load 的方案进行构建。后续交给 LLVM 直接进行优化即可。 IRbuilder.cpp (opens new window)
# LLVM
代码结构、模块化设计设计的胜利!
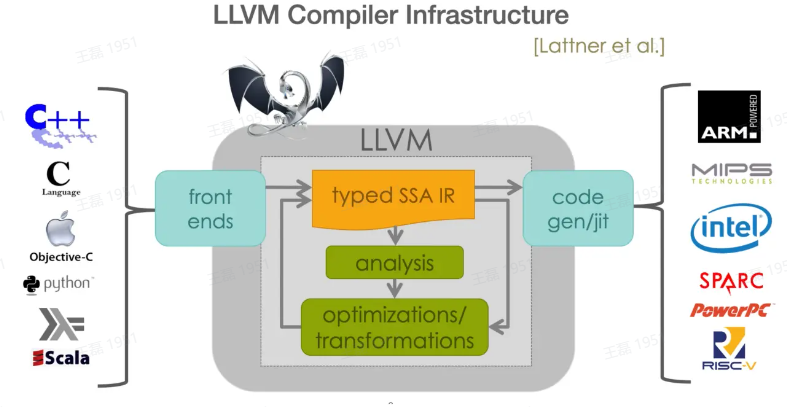
LLVM 创造性地设计了一套前中后分离的方案,让语言的前后端分离,同时中间层进行基于 SSA 形式的 LLVMIR 的
# MLIR
MLIR 一些设计是非常值得借鉴的,我们期望的尽可能通用的 SSA 正是 MLIR 也在做的。
对于语言的介入,提供了一套 IR 的表示,以及对应的 api,提供了比较方便的代码生成器快速生成定义。在 MLIR 中称为 Dialect。
对于进入 IR 以后的转换,提供了类似 LLVM 的 analyzer 和 passmanage 的组合,分析 ssa 形式 cfg 的内容并进行转换。
对于接入的语言,可以在 MLIR 的层面上进行互相转换。和 LLVM 的前中后的分离不同,MLIR 希望做的是一个中间层,其他接入 MLIR 的语言都是 Dialect,这些 Dialect 是平级关系,可以互相转换。通过这样的方式可以完成 HighLevelPL -> MLIR -> LLVM的转换,这是一个从高到低的转换,但是对于 MLIR 来说这是平级的。具体来说这是通过 PASS 机制实现的。
Toy Tutorial - MLIR (opens new window)
# DCC
一个安卓加固工具,将 dex 内的字节码转换为 c 语言的 native 层代码。 转换部分使用 androguard 库完成 cfg 的构建,然后使用的 SSA 构建方法为 [[#基于ast构造]] HowItWorks.md (opens new window) compiler.py (opens new window)