MallocLab
MallocLab
# malloclab
# 思路
在最开始写下思路吧,
按照课本上的方法,基本可以抄一遍, 然后自己写出来一个first_fit,大概得分应该在60左右, 这是种隐式链表的实现,问题出在了在从freed_chunk中取出chunk时查找会遍历根本就无用的allocted_chunk,
然后下一个思路为next_fit, 得分应该到了82左右,每次free或合并之后设置遍历起始位置, 于是在
find_fit时可以比较快速的获得到chunk, 但是不理想情况下也会进行对allocted_chunk的遍历, 毕竟这也是一种隐式链表实现,然后开始写一个显式链表, 得分应该也是82左右,不必要进行allocted_chunk的遍历了,但是每次在开头开始遍历,且size排序无意义, 也会导致效率不高, 而且每次起始位置不同next_fit命中率应该要比每次从头遍历的显式链表高一些,
接下来我开始考虑先进行realloc的优化,这时候可以得到89分, 主要就是独立成为单独的relloc而不是每次都要进入malloc和free, 思路是先考虑realloc是扩张还是缩小,如果缩小,可以直接切割后部分,如果扩张,先考虑前后chunk是否可以合并,合并后是否满足要求, 且考虑返回后内容要一致, 因此优先考虑向后拓展,最后无法获取恰好的chunk, 再考虑malloc和free,
接下来进行bin的分箱, 最开始我设计fastbin(0x10分界) + unsortedbin, 但是fastbin太小,几乎没有什么用处,繁琐的判断甚至拖累效率, 只能得到88分,
然后重新设计, seg_bins(2倍关系分界), 但是2倍会导致单个bin中的size差距还是有些大,且单向链表无序排放, 导致效率仍然比较低, 还是得到88分,
然后针对
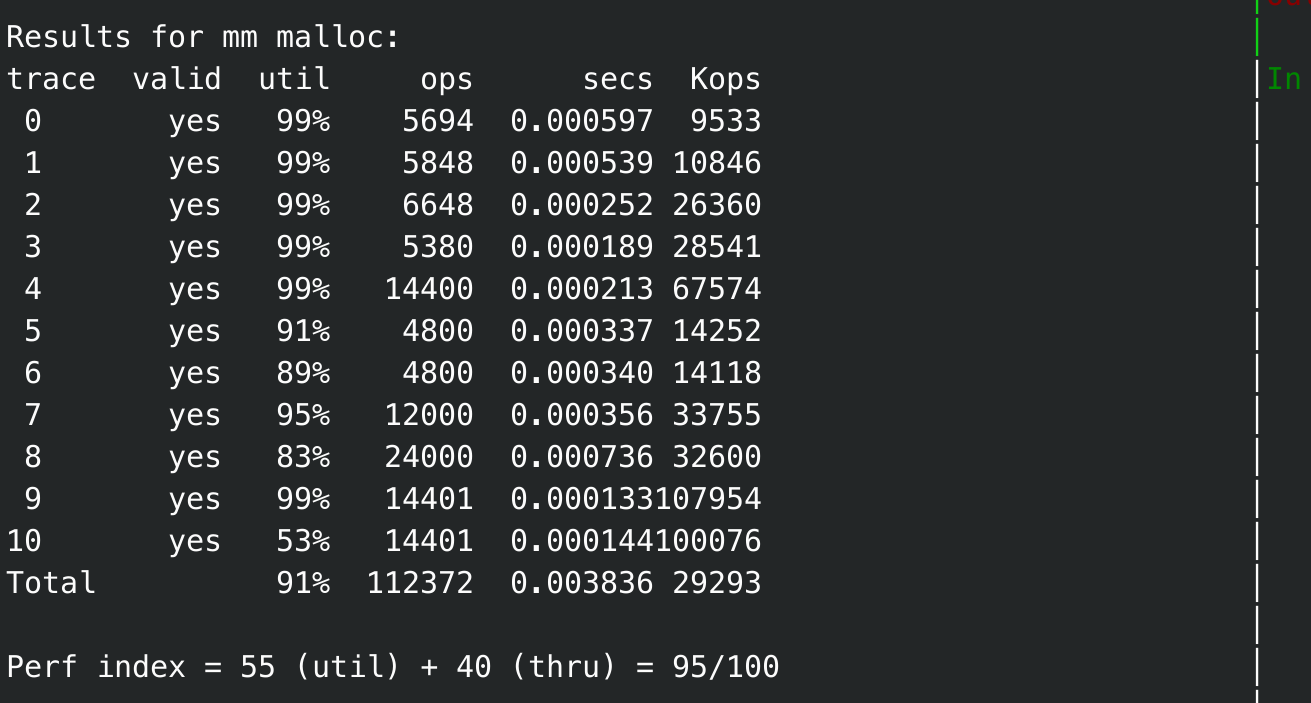
binary-bal.req优化了下, 这个主要是针对大小chunk合并机制,不仅要分箱,为了大chunk合并要进行分离,尽量小chunk在前面,大chunk在后面,优化完成可以得到91分,然后针对seg_bins进行重构, 相似的思路,采用了双向链表, 插入链表中部的操作可以比较流畅,于是使用size进行排序, 加快查找的命中率,可以得分95分,
下一步应该是针对size排序和选择进行一个优化,另外其实realloc2-bal.rep得分并不高, 属于拖累整个评分的重要原因了, 但是并没有考虑好如何处理优化,emmm, 暂时搁置。
下面是比较详细的代码:
# foot+head
一种chunk设计方案,另一种查看目录后面, [去掉foot]
# 基础宏
课本上的示例代码基本可以直接使用, 一开始就自己些宏的话错误太多, 我抄了一遍课本排错以后重新自己写的,
# chunk和memory
chunk的结构
+-------------+
| chunksize |0| <- chunk size 复用最低位判断是否在使用,
+-------------+
| | <- mem 用户使用
| (padding) |
+-------------+
| chunksize|0| <- chunk size,
+-------------+
2
3
4
5
6
7
8
9
10
在mm.c中全部使用chunk, 返回时对应减去WSIZE(为size位),
这个
chunk_index宏在下面,
#define chunk2mem(p) (chunk_index(p, WSIZE))
#define mem2chunk(mem) (chunk_index(mem, -WSIZE))
2
# chunk内数据
首先定义一个宏, 取对应地址+偏移,
#define chunk_index(p, index) ((p) + index)
然后get就是取对应位置的数据,put是对对应位置赋值,其实两种写法都是可以的,put内写get的话简洁一些,
#define get(p, index) (*(unsigned int *)chunk_index(p, index))
// #define put(p, index, val) (*(unsigned int *)chunk_index(p, index) = (val))
#define put(p, index, val) (get(p, index) = (val))
2
3
由于使用chunk, 于是这是比较常见的使用,于是专门定义个宏用来简化一些,
#define GET(p) (get(p, 0))
#define PUT(p, val) (put(p, 0, val))
2
# chunk的大小和标识位
获取大小和获取标识位,
#define GETSIZE(p) (GET(p) & ~7)
#define isuse(p) (GET(p) & 1)
2
设置大小和标识位, 同时设置head和foot,
#define inuse(p, size) \
{ \
put(p, 0, (size | 1)); \
put(p, size - WSIZE, (size | 1)); \
}
#define unuse(p, size) \
{ \
put(p, 0, size); \
put(p, size - WSIZE, size); \
}
2
3
4
5
6
7
8
9
10
11
12
# chunk的位置
相邻的前后两个chunk,
#define NEXT(p) ((char *)(p) + GETSIZE((p)))
#define PREV(p) ((char *)(p)-GETSIZE((p) - WSIZE))
2
# first_fit
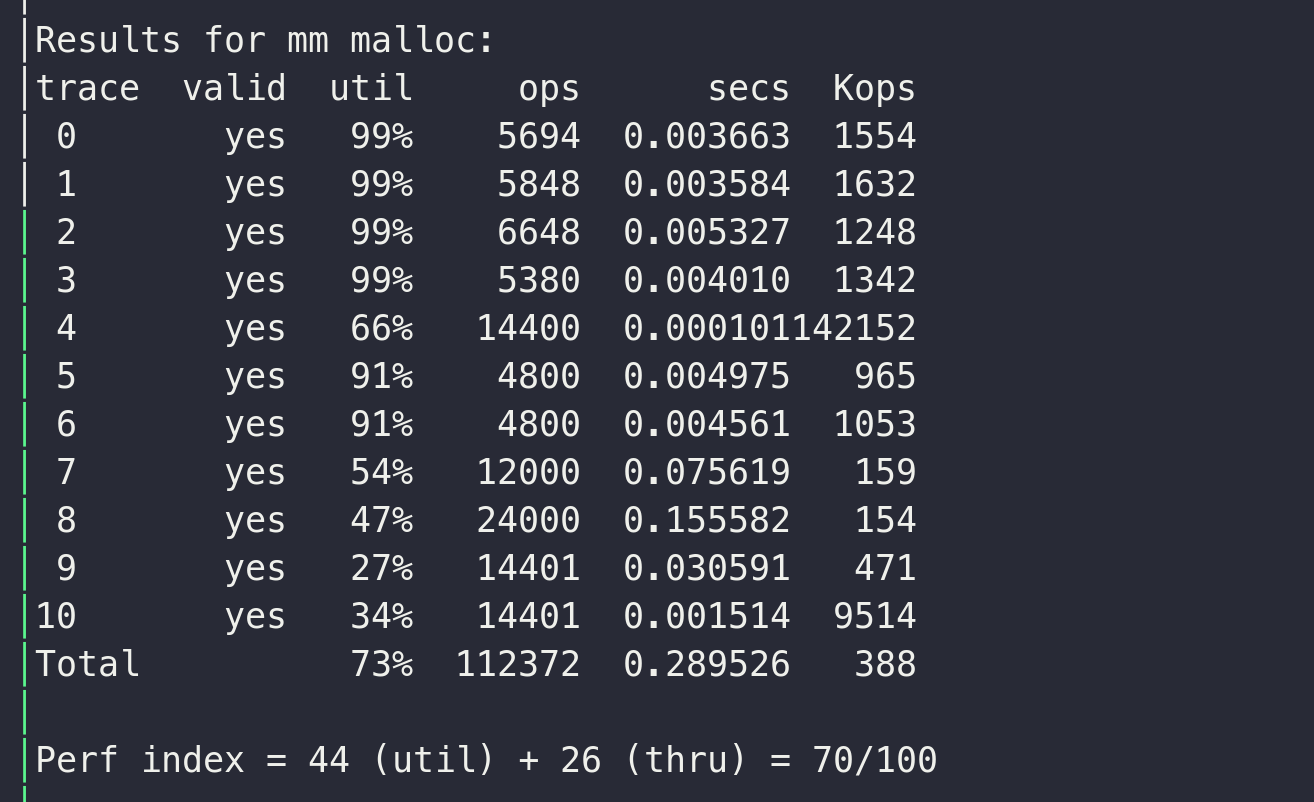
这是ppt提到的方法, 课本上有对应的代码,
大致的思路就是当查找chunk的时候首先遍历所有的chunk, 当某个chunk大小合适且为unuse状态时, 分配出来,
完整代码在github_implicit1 (opens new window),
这种方式的得分为69, 问题出在find_fit位置遍历过程低效, 且有多个无用的inuse的chunk也在遍历过程中,
详细的代码:
# mm_init
首先获取一个heap_list, 这个chunk永远为inuse状态,且后面的堆块为还未分配的chunk, 也为inuse状态,但是大小为0, 只有使用mem_sbrk才能进行拓展,
int mm_init(void) {
if ((heap_list = mem_sbrk(2 * WSIZE)) == (void *)-1)
return -1;
inuse(heap_list, DSIZE);
PUT(heap_list+2*WSIZE, 1);
if (extend_heap(CHUNK_SIZE / WSIZE) == NULL)
return -1;
return 0;
}
2
3
4
5
6
7
8
9
10
并且后面调用extend_heap, 拓展堆块,用于获取一个大chunk,并在分配过程调用find_fit时获取到,这里类似top_chunk的作用,
# extend_heap
除了在最开始mm_init初始化,使用过mem_sbrk以后, 只有这个位置才会使用,目的就是拓展出一块top_chunk,
在mm_init是会调用此函数一次,形成第一快top_chunk, 在mm_malloc中查找不到合适chunk时也会进行调用,
static void *extend_heap(int word) {
void *bp;
size_t size = (word % 2) ? ((word + 1) * WSIZE) : (word * WSIZE);
if ((bp = mem_sbrk(size)) == (void *)-1)
return NULL;
unuse(bp, size);
PUT((NEXT(bp)), 1);
return coalesced(bp);
}
2
3
4
5
6
7
8
9
10
11
12
13
# mm_malloc
malloc函数,先判断如果heap_list为空则未初始化,重新初始化, 如果size不为空,则转化为应当分配的chuunk大小newsize,
然后调用find_fit函数, 在chunk中查找不为空且大小合适的chunk, 然后调用place函数, 判断找到的chunk是否过大, 进行切割,
如果找不到的话, 说明空闲的chun不能满足, 甚至top_chunk都不行, 于是进行extend_heap获得一块大的top_chunk, 并调用place进行切割,
当然在extend_heap之前判断,如果newsize比top_chunk默认的大小还大的话,就使用newsize大小,
最后返回时使用chunk2mem宏, 转化为用户使用的指针,
void *mm_malloc(size_t size) {
int newsize;
void *tmp;
if (heap_list == NULL) {
mm_init();
}
if (size == 0) {
return NULL;
}
if (size <= DSIZE)
newsize = 2 * DSIZE;
else
newsize = WSIZE * ((size + (DSIZE) + (WSIZE - 1)) / WSIZE);
if ((tmp = find_fit(newsize)) != NULL) {
place(tmp, newsize);
return chunk2mem(tmp);
}
size_t extend_size = MAX(newsize, CHUNK_SIZE);
if ((tmp = extend_heap(extend_size / WSIZE)) == NULL)
return NULL;
place(tmp, newsize);
return chunk2mem(tmp);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# find_fit
从heap_list开始进行查找, 当size=0的chunk时结束(为top_chunk下一个,未分配的那个chunk), 然后当chunk为unuse, 且大小大于期望值size时返回对应的chunk,
static void *find_fit(size_t size) {
void *tmp = heap_list;
for (tmp = heap_list; GETSIZE((tmp)) > 0; tmp = NEXT(tmp)) {
if (((!isuse((tmp)))) &&
(GETSIZE((tmp)) >= (unsigned int)size)) {
return tmp;
}
}
return NULL;
}
2
3
4
5
6
7
8
9
10
# place
进行切割, 如果chunk大小比size大了一个最小chunk大小(4×WSIZE), 则进行切割,
static void place(void *p, size_t size) {
size_t psize = GETSIZE((p));
if ((psize - size) >= (2 * DSIZE)) {
inuse(p, size);
unuse(NEXT(p), (psize-size));
} else {
inuse(p, psize);
}
}
2
3
4
5
6
7
8
9
# mm_free
判断ptr不为0, 然后mem2chunk宏进行转化, unuse设置为unuse状态, 并调用coalesced函数进行合并,
void mm_free(void *ptr) {
if (ptr == 0)
return;
void* tmp = mem2chunk(ptr);
size_t size = GETSIZE((tmp));
unuse(tmp, size);
coalesced(tmp);
}
2
3
4
5
6
7
8
# coalesced
先判断chunk的相邻前后chunk是否在使用, 直接进行合并,
static void *coalesced(void *p) {
size_t prev_use = isuse((PREV(p)));
size_t next_use = isuse((NEXT(p)));
size_t size = GETSIZE((p));
if (prev_use && next_use) {
return p;
} else if (prev_use && (!next_use)) {
size += GETSIZE((NEXT(p)));
unuse(p, size);
} else if ((!prev_use) && next_use) {
size += GETSIZE((PREV(p)));
p = PREV(p);
unuse(p, size);
} else if ((!prev_use) && (!next_use)) {
size += GETSIZE((PREV(p))) + GETSIZE((NEXT(p)));
p = PREV(p);
unuse(p, size);
}
return p;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# mm_realloc
判断ptr为null、 size为0以后, 直接重新malloc一个chunk, memcpy进行复制,并free掉原来的ptr即可,
tip
这里应该注意,调用malloc free等事,返回和传入的是用户使用的memory, 于是这个realloc应该全部使用的指针是memory而非chunk,
另外使用宏时也应该增加一层mem2chunk,
void *mm_realloc(void *ptr, size_t size) {
void *p;
size_t copy_size;
if (ptr == NULL) {
p = mm_malloc(size);
return p;
}
if (size == 0) {
mm_free(ptr);
return NULL;
}
copy_size = GETSIZE(mem2chunk(ptr));
p = mm_malloc(size);
if (!p) {
return NULL;
}
if (size < copy_size)
copy_size = size;
memcpy(p, ptr, copy_size);
mm_free(ptr);
return p;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
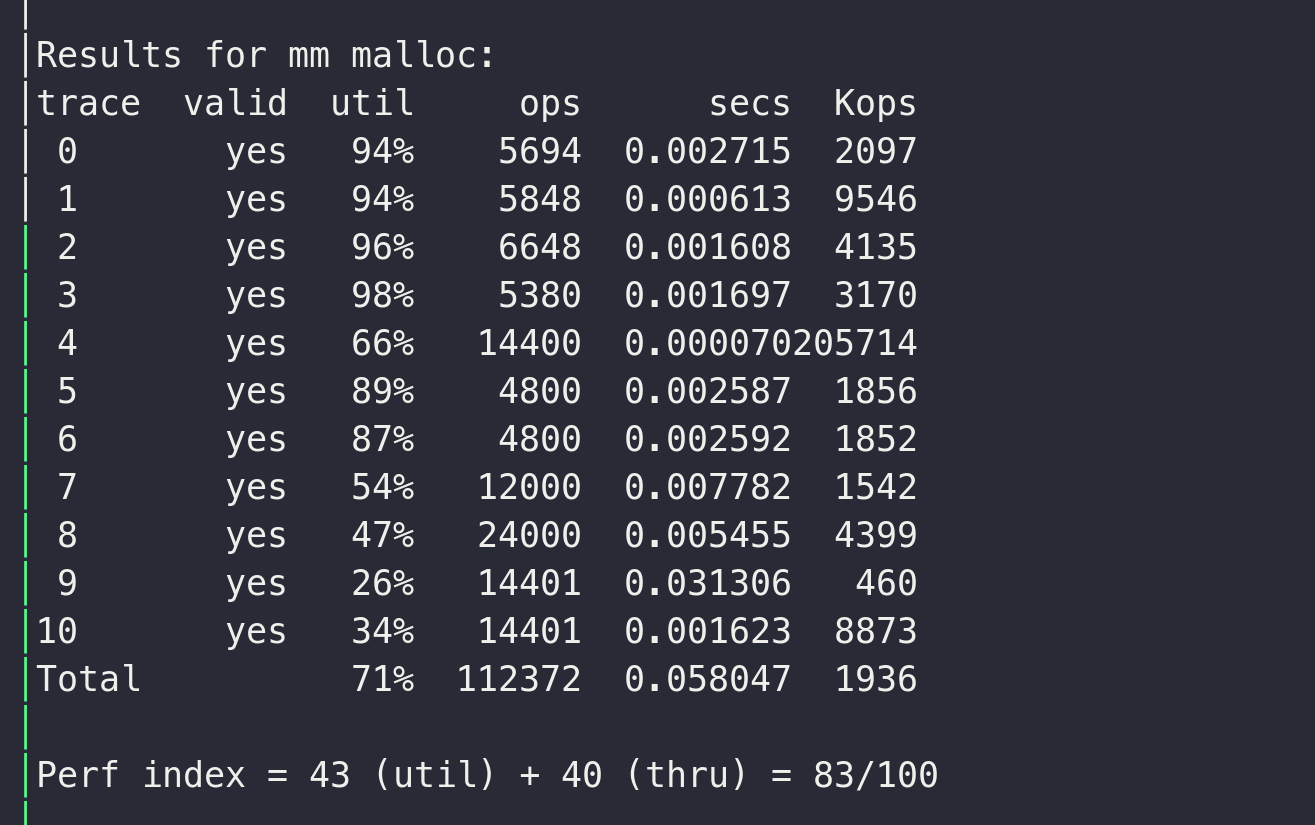
# next_fit
这是课本提到的一种方案,在更可能命中的位置开始遍历,但是仍然使用在隐式链表,遍历中会有inuse的chunk, 仍然会导致效率问题,
代码在github_implicit2 (opens new window)
这种方案可以达到83分
详细代码:
# find_point
定义一个全局变量,find_point,表示开始遍历的位置,
# find_fit
主要的改变是,首先从find_point开始遍历,如果遍历不到,再开始从heap_list遍历到find_point,
static void *find_fit(size_t size) {
void *tmp;
tmp = find_point;
while (GETSIZE(tmp) > 0) {
if ((!isuse(tmp)) && (GETSIZE(tmp) >= (unsigned int)size)) {
return tmp;
}
tmp = NEXT(tmp);
}
tmp = heap_list;
while (tmp != find_point) {
if ((!isuse(tmp)) && (GETSIZE(tmp) >= (unsigned int)size)) {
return tmp;
}
tmp = NEXT(tmp);
}
return NULL;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 设置find_point
在调用extend_heap以后,find_point指向新的top_chunk,
在调用coalesced以后, find_point指向合并后的chunk,
# 去掉foot
这是提到的一个思路,其实并不会怎样影响效率,但是chunk的结构有一定变化,
得分仍然是83, 代码在github_implicit3 (opens new window)
# 结构
free chunk的结构
+---------------+
| chunksize |0|0| <- chunk size
+---------------+
| | <- mem 用户使用
| (padding) |
+---------------+
| chunksize | <- chunk size,
+---------------+
malloc chunk的结构
+---------------+
| chunksize |0|1| <- chunk size
+---------------+
| | <- mem 用户使用
| |
| (padding) |
+---------------+
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 基础宏
判断上一个chunk是否在使用
#define prev_isuse(p) ((GET(p) & 2) >> 1)
在设置inuse, unuse时同时设置下一个chunk的prev_inuse位
#define PREV_INUSE 2
#define inuse(p, size) \
{ \
put(p, 0, (size | 1 | (prev_isuse(p) << 1))); \
put(p, size, (GET(NEXT(p)) | PREV_INUSE)); \
}
#define unuse(p, size) \
{ \
put(p, 0, (size | (prev_isuse(p) << 1))); \
put(p, size - WSIZE, size); \
put(p, size, (GET(NEXT(p)) & (~))); \
}
2
3
4
5
6
7
8
9
10
11
12
13
14
warning
其他位置其实并没有改动, PRVE查找上一个堆块还是原来的,代码中注意在确定prev处于unuse才可以使用PREV获得上个chunk,
不然获取到的prev_size=0, PREV以后仍然是自己,
另一个重要的点在于去掉foot以后, mm_malloc中的newsize应该只需要比用户申请的size大WSIZE, 存放一个size位即可,
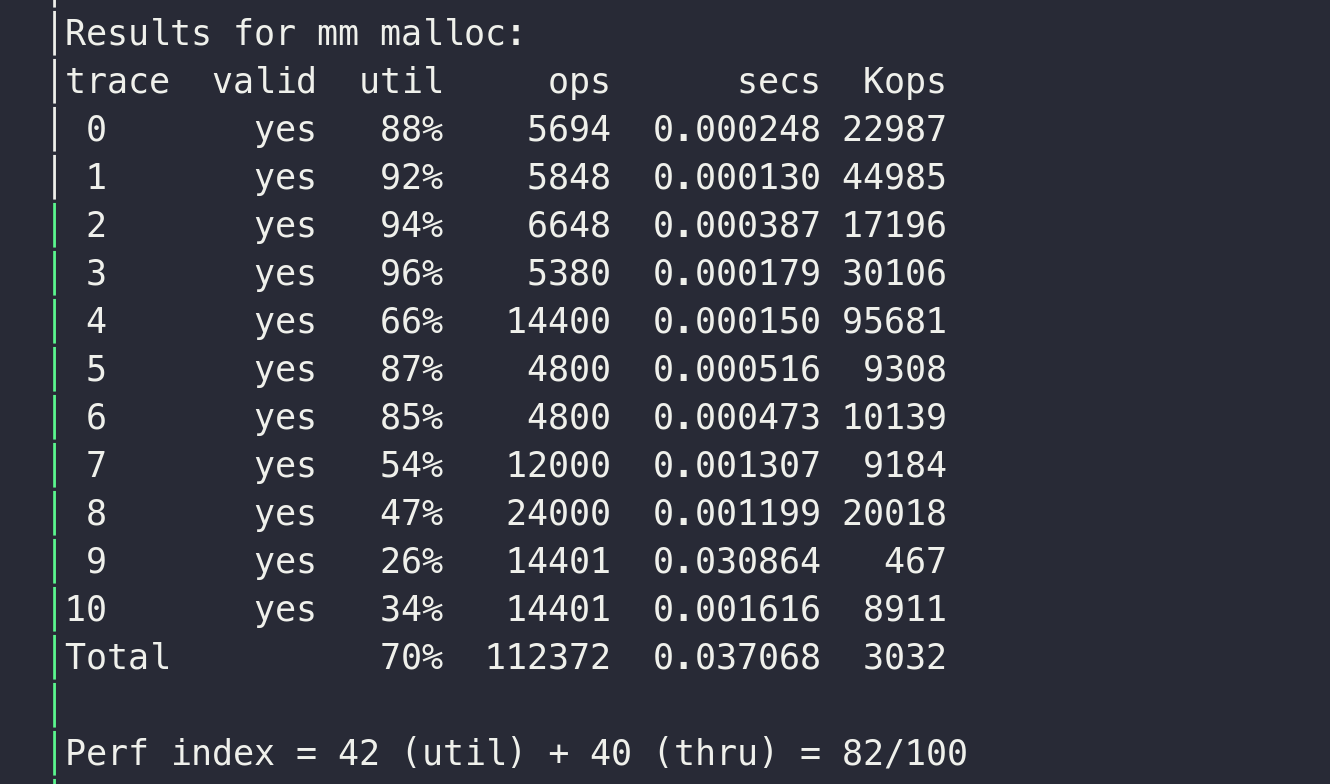
# explicit
使用显示链表,将unuse状态的chunk使用双向链表全部连接起来,这样在遍历的时候避免了遍历inuse状态的chunk, 可以提高效率,也有chunk结构变化
代码在github_explicit1 (opens new window)
这种方案得分 82,
# 结构
增加了FD和BK指针
free chunk的结构
+---------------+
| chunksize |0|0| <- chunk size
+---------------+
| FD | <- mem 用户使用
| BK |
| (padding) |
+---------------+
| chunksize | <- chunk size,
+---------------+
2
3
4
5
6
7
8
9
10
11
每次free会插入到heap_list为表头的双向链表尾部,每次遍历会从heap_list开始遍历一遍,
# 新的宏
设置链表前后指针和获取对应指针,和插入到链表尾部、从链表中取出的宏,
(unlink 危
#define FD(p) (*((unsigned long *)chunk_index(p, WSIZE)))
#define BK(p) (*((unsigned long *)chunk_index(p, 2 * WSIZE)))
#define link(p) \
{ \
BK(p) = BK(heap_list); \
FD(p) = (unsigned long)heap_list; \
BK(heap_list) = (unsigned long)p; \
FD(BK(p)) = (unsigned long)p; \
}
#define unlink(p) \
{ \
BK(FD(p)) = BK(p); \
FD(BK(p)) = FD(p); \
FD(p) = nil; \
BK(p) = nil; \
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
为了原本的代码不改动,
设置新的inuse和unuse, 包含了链表操作,并且将原本的修改为set_inuse, set_unuse,
#define set_inuse(p, size) \
{ \
put(p, 0, (size | 1 | (prev_isuse(p) << 1))); \
put(p, size, (GET(NEXT(p)) | PREV_INUSE)); \
}
#define inuse(p, size) \
{ \
unlink(p); \
set_inuse(p, size); \
}
#define set_unuse(p, size) \
{ \
put(p, 0, (size | (prev_isuse(p) << 1))); \
put(p, size - WSIZE, size); \
put(p, size, (GET(NEXT(p)) & (~PREV_INUSE))); \
}
#define unuse(p, size) \
{ \
link(p); \
set_unuse(p, size); \
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# mm_init
设置好heap_list以后,先形成一个双向链表表头,
int mm_init(void) {
if ((heap_list = mem_sbrk(4 * WSIZE)) == (void *)-1)
return -1;
BK(heap_list) = FD(heap_list) = (size_t)heap_list;
set_inuse(heap_list, 4 * WSIZE);
PUT(NEXT(heap_list), (CHUNK_INUSE | PREV_INUSE));
if (extend_heap(CHUNK_SIZE / WSIZE) == NULL)
return -1;
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
# find_fit
从heap_list开始遍历双向链表,
static void *find_fit(size_t size) {
void *tmp;
tmp = (void *)BK(heap_list);
while (tmp != heap_list) {
if (GETSIZE(tmp) >= (unsigned int)(size)) {
return tmp;
}
tmp = (void *)BK(tmp);
}
return NULL;
}
2
3
4
5
6
7
8
9
10
11
# 其他
其他位置几乎没有啥变化,因为设置了新的unuse, inuse, 会自动维护链表, 问题不是很大,
# realloc优化
这是设置独立的realloc, 针对最后两个trace进行优化。
代码在github_realloc (opens new window)
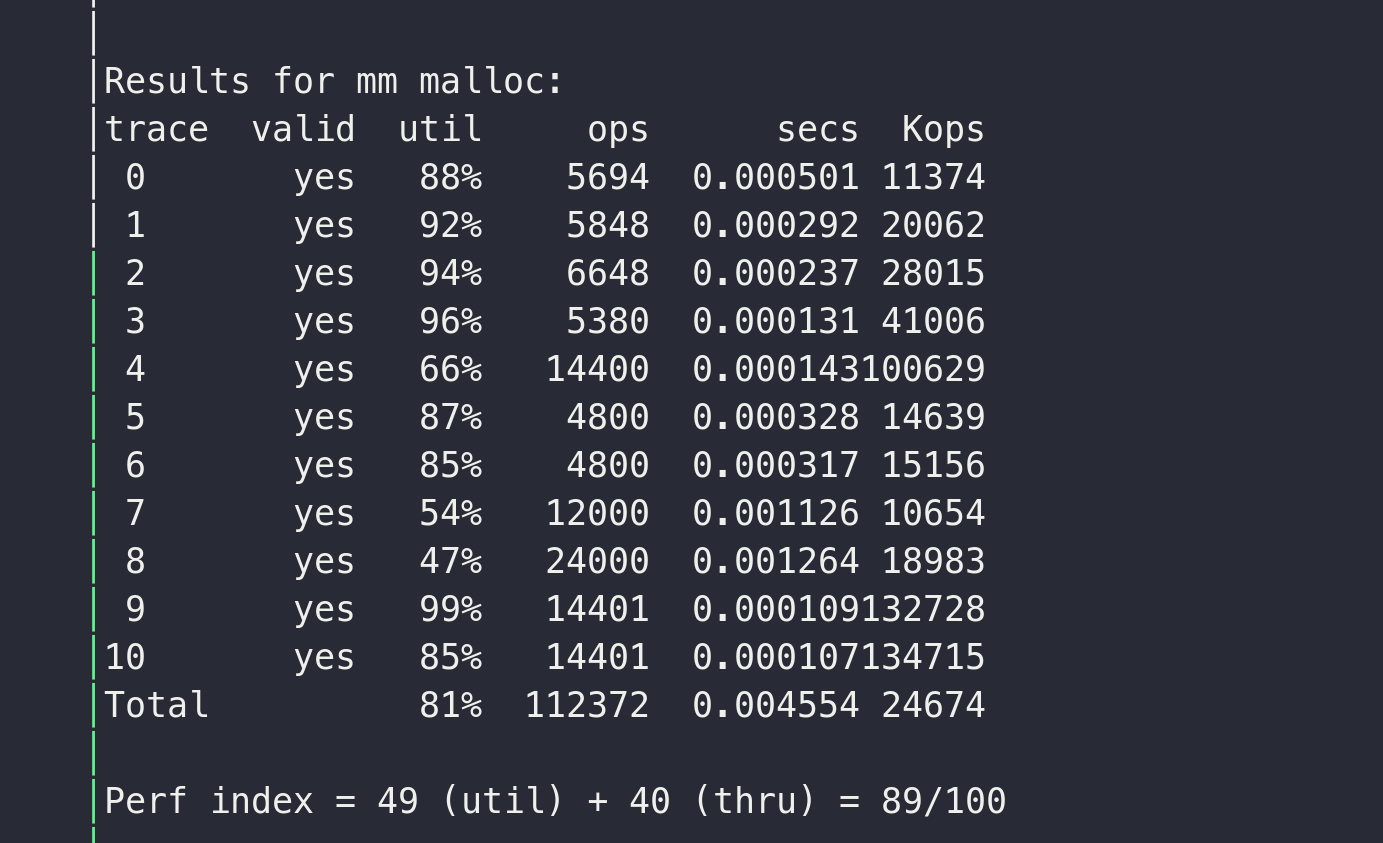
由于之前的realloc是转向使用malloc和free, 导致效率不高, 这里进行一个优化, 最后得分89,
# 简述思路
其实思路比较简单,
首先获取对应的chunk大小oldsize和要更新的大小newsize,
如果oldsize<newsize, 则可以进判断和切割, 调用一个类place的函数realloc_place,
如果oldsize>newsize, 则判断前后是否可以合并, 然后判断切割,先调用类coalesced函数realloc_coalesced, 然后调用类place函数realloc_place, 如果不行, 则再转向使用malloc和free,
如果都不是,则oldsize=newsize, 直接返回即可,
另外如果获取到的指着和原指针一致,直接返回, 如果不一致需要memcpy, (合并前一个chunk时, 调用malloc+free时)
# mm_realloc
如上所述的思路,
注意如果合并的prev_chunk, 要在memcpy以后再进行realloc_place, 不然可能修改到ptr, 导致数据不同,
void *mm_realloc(void *ptr, size_t size) {
size_t oldsize, newsize;
void *tmp, *p, *newptr;
if (ptr == NULL) {
p = mm_malloc(size);
return p;
}
if (size == 0) {
mm_free(ptr);
return NULL;
}
tmp = mem2chunk(ptr);
oldsize = GETSIZE(tmp);
/*newsize = size + WSIZE;*/
if (size <= DSIZE)
newsize = 2 * DSIZE;
else
newsize = WSIZE * ((size + (DSIZE) + (WSIZE - 1)) / WSIZE);
if (oldsize > newsize) {
p = realloc_place(tmp, newsize, oldsize);
newptr = chunk2mem(p);
return newptr;
} else if (oldsize < newsize) {
p = realloc_coalesced(tmp, newsize, oldsize);
if (p == NULL) {
newptr = mm_malloc(newsize);
memcpy(newptr, ptr, oldsize);
mm_free(ptr);
return newptr;
} else {
newptr = chunk2mem(p);
if (newptr == ptr) {
return newptr;
} else {
memcpy(newptr, ptr, oldsize - WSIZE);
realloc_place(p, newsize, GETSIZE(p));
return newptr;
}
}
}
return ptr;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
# realloc_colesced
这里同样注意,如果合并了prev_chunk, 不能直接调用realloc_place, 要返回, 调用memcpy后才可以,
但是如果是只合并next_chunk的话,可以直接调用realloc_place 然后返回,因为这样在realloc中返回的newptr和原本的ptr是同样的,不需要复制,也不会被修改数据,
static void *realloc_coalesced(void *tmp, size_t newsize, size_t oldsize) {
void *p;
size_t prev_use = prev_isuse(tmp);
size_t next_use = isuse((NEXT(tmp)));
size_t size = oldsize;
if (prev_use && next_use) {
} else if ((!next_use)) {
size += GETSIZE((NEXT(tmp)));
if (size >= newsize) {
unlink(NEXT(tmp));
set_inuse(tmp, size);
return realloc_place(tmp, newsize, size);
}
} else if ((!prev_use) && next_use) {
size += GETSIZE((PREV(tmp)));
if (size >= newsize) {
unlink(PREV(tmp));
set_inuse(PREV(tmp), size);
return PREV(tmp);
}
} else if ((!prev_use) && (!next_use)) {
size += GETSIZE((PREV(tmp))) + GETSIZE((NEXT(tmp)));
if (size >= newsize) {
unlink(PREV(tmp));
unlink(NEXT(tmp));
set_inuse(PREV(tmp), size);
return PREV(tmp);
}
}
return NULL;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
# realloc_place
某次由于newsize的bug注释了下, 发现注释中的正确的逻辑, 速度比较慢, 甚至和不优化realloc时速度相同, 于是按照下面的直接设置并返回,速度就比较快,
注意这里使用set_inuse,因为在realloc_coalesced中已经进行了unlink操作,
static void *realloc_place(void *tmp, size_t newsize, size_t oldsize) {
// this way will be slow
/*if ((oldsize - newsize) > (2 * DSIZE)) {*/
/*set_inuse(tmp, newsize);*/
/*unuse(NEXT(tmp), (oldsize - newsize));*/
/*} else {*/
/*set_inuse(tmp, oldsize);*/
/*}*/
// this way will be fast
set_inuse(tmp, oldsize);
return tmp;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 分类link
这个就是实现对不同size的分箱,
这个分类我写了两套,
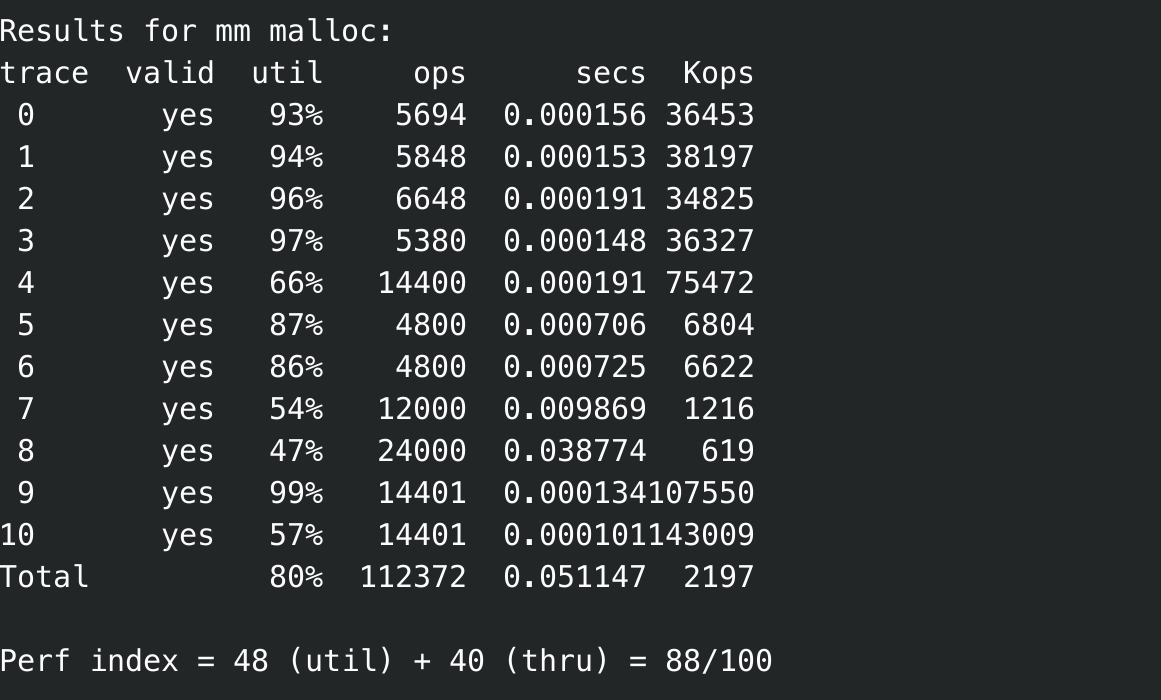
最开始想模仿glibc, 于是fastbin(以0x10间隔) + unsorted bin, 但是并没有解决之前对对应size的find_fit函数中的命中率问题, 因此分数反而因为操作繁琐降低了,
写完以后才意识到,根本问题不是分箱size就会快, 而是分箱size以后提高了find_fit的命中率, 于是只有一个seg_bins, 以2倍分割, 从最小0x20到0x1000, 更大的size也会放到0x1000的bin中,
但是这里2倍导致单个bin中size的大小差值还是比较大,即使在某个bin中查找,但是仍然效率不高, 仍然在88分,和上一个基本差别不大,
期间, 突然发现./trace/binary*两个评分样例的规则是, 先malloc小大小大小大规则chunk,然后free掉大的chunk, 再malloc大一点点的chunk, 这时候如果小chunk在中间就会导致大chunk之间无法合并,这时候会遍历整个链表,仍然不能找到满足的chunk, 优化方案就是在malloc的时候,切割函数place保证大chunk在后面,小chunk在前面,
优化的place()
通过判断临界条件88, 大chunk在后, 小chunk在前,
static void *place(void *p, size_t size) {
size_t psize = GETSIZE((p));
if ((psize - size) < (2 * DSIZE)) {
inuse(p, psize);
} else if (size >= 88) {
unuse(p, (psize - size));
inuse(NEXT(p), size);
return NEXT(p);
} else {
inuse(p, size);
unuse(NEXT(p), (psize - size));
}
return p;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
而其中的分界点可以这样计算
binary-bal.rep的size分别为:64, 488, free后再malloc的size为512,
binary2-bal.rep的size分别为16, 112, free后再malloc的size为128,
则我们希望16, 64被认为是小chunk, 而112, 128, 488, 512被认为是大chunk,
取两个边界64, 112其中任意一个都应该可以达到目的, 这里取(64+112)/2 = 88
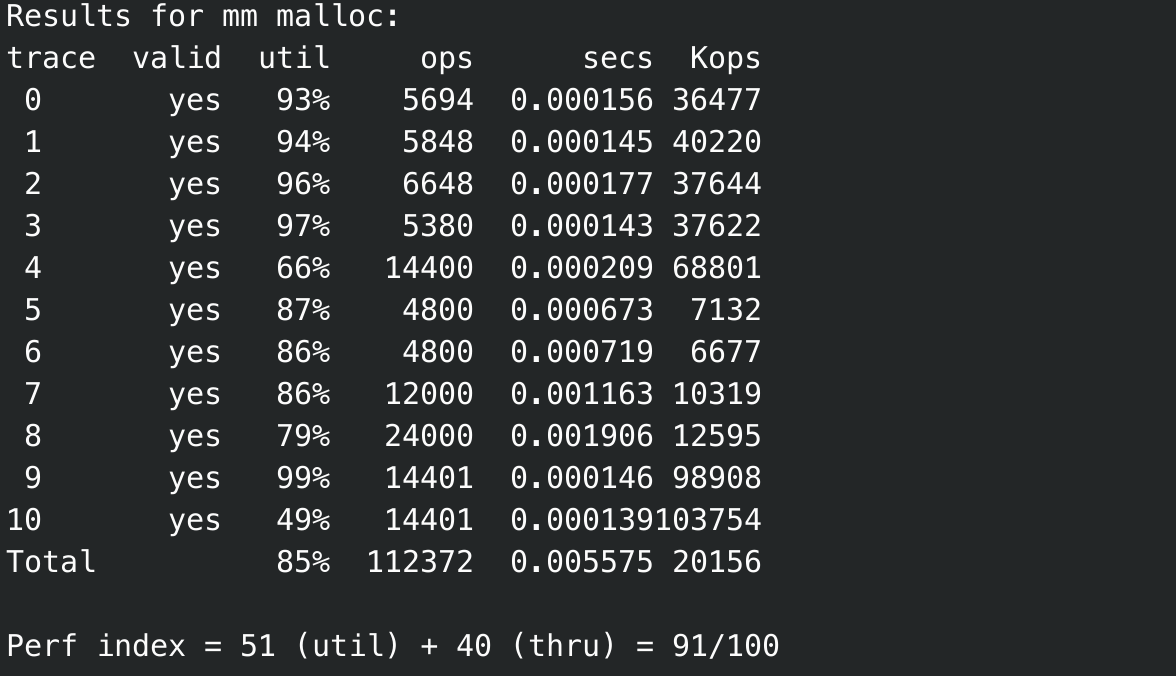
这样的优化可以提高效率, 大概可以达到91分了,
但是仍然在find_fit位置没有处理的很好,
这时候我们重构原来的思路, 并且每次free后插入bin中的时候先比较size, 按照size形成对应的bin链表, 并且将原来宏写成的link, unlink修改为函数mm_link, mm_unlink, 这样的设计比较好的解决了问题, 可以获得95分,