 pdf format
pdf format
# pdf format
# 总览
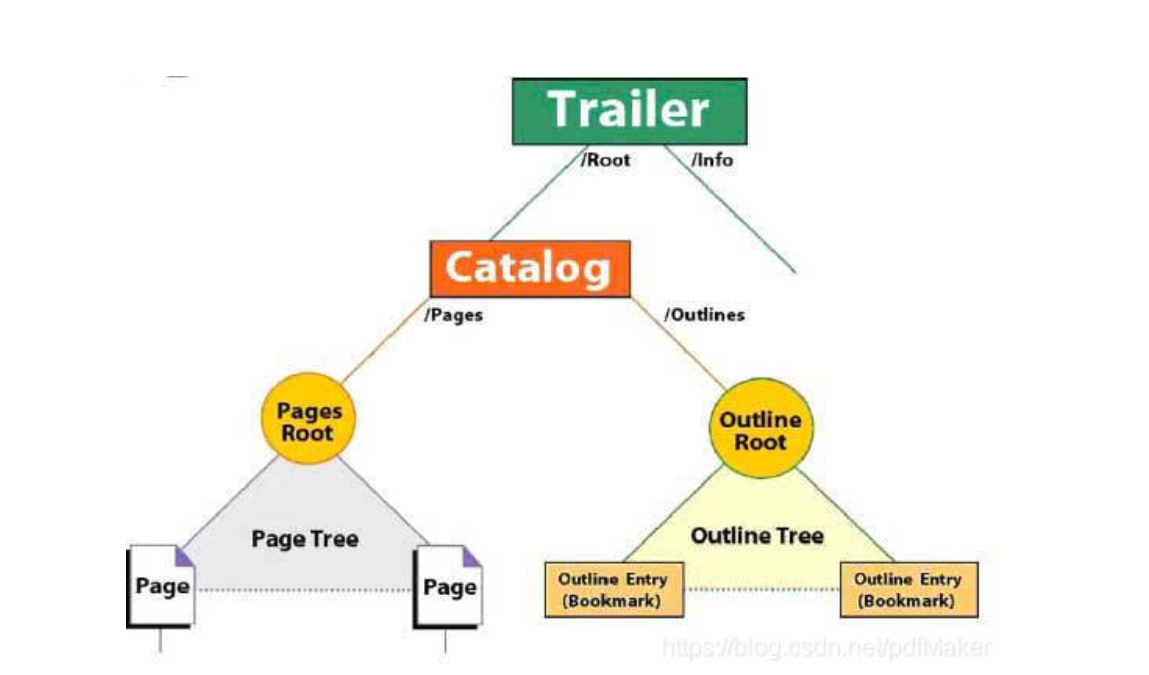
pdf基本组成分为四部分,
- header 文件头, 用来表示该文件遵循的pdf规范的版本号,一定是在文件的第一行。
- body 文件提, 这是pdf文件的主要部分, 由一系列对象组成,这些对象用来表示pdf内容的主体。
- xref table 交叉引用表, 相当于是pdf内所有对象的一个地址索引表, 为了保证pdf对象可以进行随机存储。
- trailer 文件尾, 声明了交叉引用表的地址, 也声明了pdf的文件体的根对象
Catalog的地址 ,
其实主要的思路就是将所有的相关数据全部做成一个个的对象obj,
每个对象的定义从obj_num gen_num obj开始, 从endobj结束,其中obj_num 和gen_num 是该对象的对象号和产生号, 我们在其他位置可以通过这两个号码对某个对象进行引用。
pdf的内容就是通过一个个表示各种属性或者意义的对象通过相互引用的逻辑组成的,
所以最重要的结构其实就是body , xref table只是为了进行对象的索引, trailer主要的意义就是定义到xref table和文件的根对象Catalog。
# pdf基本语法
基本就是对于对象的定义,
obj_num gen_num obj
<<
/Type /Pages
/Count 1
/Kids [4 0 R]
/..
>>
stream
...
endstream
endobj
2
3
4
5
6
7
8
9
10
11
在pdf中, 一个obj的定义需要指定obj_num, gen_num, 然后其他对象可以通过这个号引用他,比如我们Kids [4 0 R]这里就是引用了一个 4 0号对象,
对象内使用<< >>括起来,在代码实现可以看作是个字典,然后其中的[] 中的是数组,字段通过/xxx表示,对应的数据可以是字典 数组 数字也可以是另一个字段。
stream到endstream之间是数据流部分,一般某些不可打印的数据会存在这个位置。
# hellow-world.pdf 分析
首先是文件头,表示符合pdf 1.7规范,

然后是第一个对象,
1 0 obj % entry point
<<
/Type /Catalog
/Pages 2 0 R
>>
endobj
2
3
4
5
6
类型 Catalog表示是根对象, Pages表示这个根对象包含的页面, 2 0 R表示对对象2 0的引用
2 0 obj
<<
/Type /Pages
/MediaBox [ 0 0 200 200 ]
/Count 1
/Kids [ 3 0 R ]
>>
endobj
2
3
4
5
6
7
8
2号对象就是这个Pages, MediaBox表示页面现实大小,(以像素为单位), Count表示页码数量为1, 有多少个页面就会有多少个对页面对象的引用, Kids表示这个引用, 现在只有一个页面, 是一个对3 0的引用。
3 0 obj
<<
/Type /Page
/Parent 2 0 R
/Resources <<
/Font <<
/F1 4 0 R
>>
>>
/Contents 5 0 R
>>
endobj
2
3
4
5
6
7
8
9
10
11
12
Page对象,Parent表示其父对象 即Pages对象,Rsources表示页面内要包含的资源,这里展示的是字体。Contents表示页面内容对应的对象。
4 0 obj
<<
/Type /Font
/Subtype /Type1
/BaseFont /Times-Roman
>>
endobj
2
3
4
5
6
7
表示为一个字体类型,
5 0 obj % page content
<<
/Length 44
>>
stream
BT
70 50 TD
/F1 12 Tf
(Hello, world!) Tj
ET
endstream
endobj
2
3
4
5
6
7
8
9
10
11
12
Length表示stream的字节数,其中stream到endstream表示一个流对象, BT 到ET表示一个文字对象,
/F1 12 Tf表示 为True font对象,字体名 F1, 大小为12个像素。
xref
0 6
0000000000 65535 f
0000000010 00000 n
0000000079 00000 n
0000000173 00000 n
0000000301 00000 n
0000000380 00000 n
2
3
4
5
6
7
8
再往后就是xref索引表, 这个表中的 0 6表示, 从0开始计算,一共存在6个对象,
后续的每一行表示一个对象,按照 起始地址-产生号表示,其中 f表示空闲对象,n表示在使用中的对象,
第一个对象其实是表示的文件头。
trailer
<<
/Size 6
/Root 1 0 R
>>
startxref
492
%%EOF
2
3
4
5
6
7
8
最后几行是文件结束,给出了根对象 Catalog, xref的起始地址。
最后 %%EOF表示文件结束地址。
# pdf文件解析过程
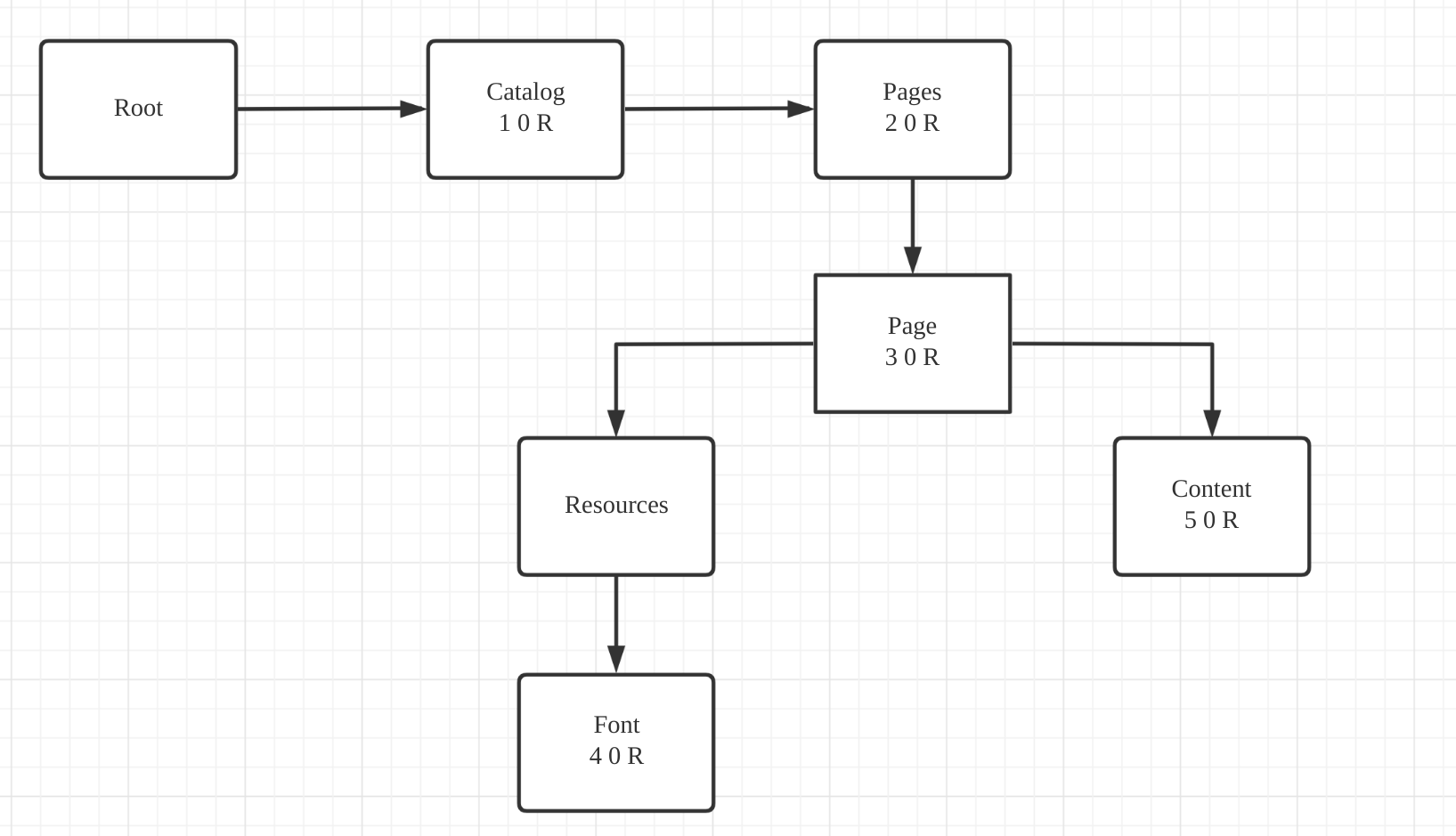
于是我们可以了解到这个文件解析过程,
首先是从最后开始,索引到xref table, 建立起索引表,然后获取到 Catalog对象,并开始依次查找下去。
上面提到的实例文件的解析过程大概如下,
# Type/Xref
在比较新一些的pdf格式中( pdf 1.5 之后),为了压缩格式,已经可以支持将 xref写在对象中,
从原本的 xref table变成 xref stream, 交叉引用流对象。
这个设计的好处如下:
- 在stream可以二进制方案储存数据,这样可以引入一些压缩算法使文件结构紧凑。
- 引申出
ObjStm对象 储存在stream中的对象。 - 提供了可拓展的交叉引用流类型
其实应该算是增强我们前面看到的stream的使用,将xref table放在stream 中,甚至将一个对象放在 stream中,引申出来 /Type/Xref 和 /Type/ObjStm对象,这样可以在stream中采用压缩方案,
而且对于我们之前提到的文件格式来说,可以在 Xref对象中指定根对象的位置, 不需要xref table的偏移地址,pdf解析器会自动寻找所有对象并获取到 Xref对象和ObjStm对象并进行解析。
于是pdf结构基本只剩下了 文件头+文件体 + %%EOF。
一个样例如下:
14 0 obj
<<
/DecodeParms
<<
/Columns 4
/Predictor 12
>>
/Filter/FlateDecode
/ID[<E78A5BE5FCF11A47A3624166A69CDD42><5AF19636F75D4B418D351158DE589CA7>]
/Info 60 0 R
/Length 82
/Root 62 0 R
/Size 61
/Type/XRef
/W[1 2 1]
>>stream
....
endstream
endobj
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 压缩+过滤
可以执行一些压缩算法,
在xref对象中可以通过参数进行指定。
对于xref stream中的数据, 压缩算法使用zlib, 通过/Filter/FlateDecode指定使用 FlateDecode进行解压。
然后解压后的数据要进行过滤处理, DecodeParms决定,
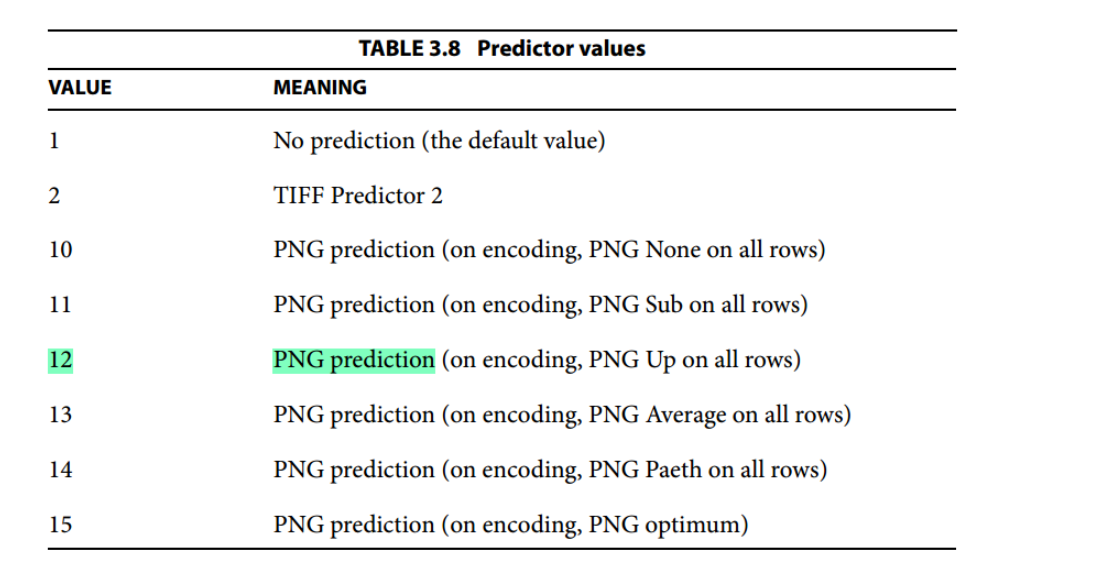
其中的/Predictor 12指定过滤器处理算法, 这个参数的其他取值如下:
# 参考
一个简单PDF文件的结构分析 (opens new window)
PDF 参照流/交叉引用流对象(cross-reference stream)的解析方法 (opens new window)